
LangChat Pro 商业白皮书
产品概述
LangChat Pro 是面向企业生产环境构建的 AI 应用开发与运行平台,基于企业级 Java 生态,提供从模型接入、知识工程、工作流编排到 Agent 发布的完整闭环,帮助团队快速完成私有化落地与系统集成。
平台采用模块化分层架构,重点强化 Skills 与 Sandbox 运行能力:支持 Skills 包导入、在线编辑、版本管理与自动化部署,可按任务自动绑定本地或 Sandbox 运行环境,在保障执行效率的同时实现隔离执行与风险收敛。面向交付阶段,平台支持 Agent 一键发布到 API、企业微信、钉钉、飞书、公众号等多渠道,满足企业从开发、验证到上线运营的全流程需求。
商业合作与咨询微信:LangchainChat (添加时请备注公司名称)

核心系统架构与底层支撑
现代化工程技术栈选型
LangChat 深度融合当下主流的企业级技术生态,保障系统的易维护性与二次开发效率。
- 稳健的后端架构:依托 Spring Boot 3.x 及 JDK 17+ LTS,全面兼容高并发企业业务场景。持久层采用 MySQL 8.0+ 搭配 MyBatis-Plus 3.5+。
- 前沿的前端平台:基于 Vue 3.4+ (Composition API)、TypeScript 5.0+ 与 NaiveUI 打造极致交互,结合自定义 VueFlow 节点实现直观的工作流拓扑编排。
- 企业级 AI 中枢:底层深度整合 LangChain4j,提供标准化的大模型统一切换层、动态 Tool/Function Calling 机制、流式对话(SSE)与执行链路追踪能力。
信创生态与国产化支持
系统深度适配各类国产信创化标准软硬件环境,满足政企机构对安全性与自主可控的核心要求。
- 信创数据库无痕适配:通过标准化 JDBC 接口及 MyBatis-Plus 动态路由引擎,少量修改即可兼容达梦、人大金仓、南大通用、优炫、星瑞格等十余款主流国产信创数据库。
模型网关与聚合接入
构建了极其灵活的统一模型抽象层,一键无缝切换国内外主流通用大模型与私有化本地模型。
- 国内核心大模型生态:全面集成 深度求索 (DeepSeek-R1/Coder)、阿里百炼 (Qwen 全系)、百度千帆 (ERNIE-Bot)、智谱清言 (GLM-4)、字节豆包及硅基流动等。
- 国际顶级大模型生态:无缝支持 OpenAI (GPT-4/dall-e)、Google (Gemini)、Azure OpenAI 企业级端点。
- 私有化开源模型推理:适配 Ollama、vLLM、Xinference 及 GpuStack 等高性能本地推理框架。
Skills 与 Sandbox 运行底座
围绕企业可运营的技能体系,平台提供标准化开发、自动化部署与可追踪执行能力。
- Skills 标准化管理:支持 ZIP 技能包导入、在线脚本编辑、元数据维护与版本迭代,降低技能资产沉淀门槛。
- 自动化部署与挂载:支持在 Agent/Workflow 中按节点或场景快速挂载 Skills,并可根据配置自动绑定本地或 Sandbox 运行环境。
- 隔离执行与安全控制:基于 OpenSandbox 提供容器级隔离执行能力,控制文件系统与依赖边界,降低宿主环境越权风险。
- 可观测运行链路:支持执行日志、输入输出与故障定位能力,便于团队排障和持续优化。
多渠道发布与交付能力
面向企业上线阶段,平台提供统一发布入口与多渠道分发机制。
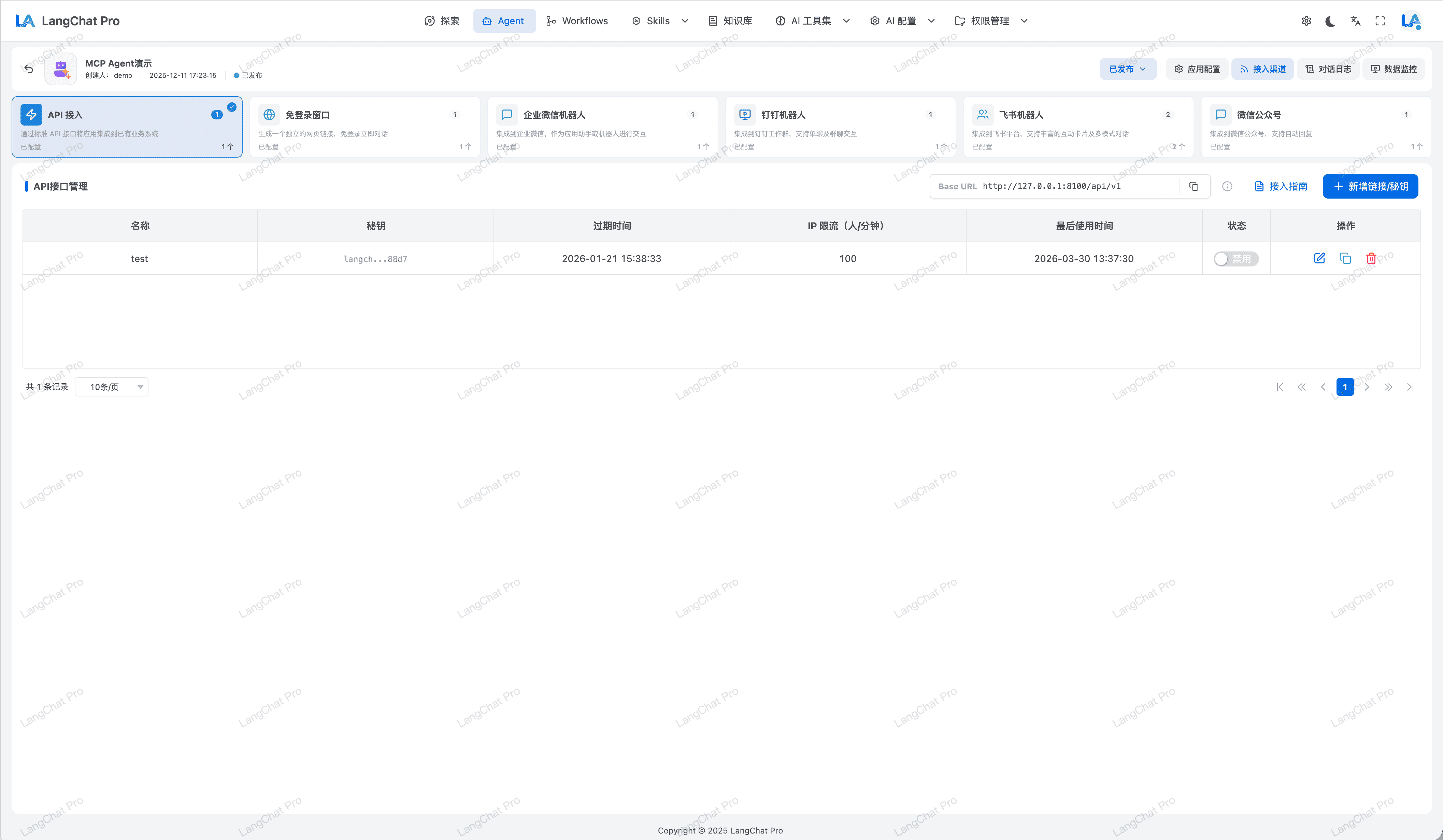
- 统一发布入口:支持将 Agent 快速发布为 API 服务或对话应用,减少重复对接工作。
- 多渠道覆盖:原生支持企业微信、钉钉、飞书、公众号等渠道,满足不同业务触点的接入需求。
- 交付一致性:保持提示词、工具链路与技能配置在多渠道侧一致运行,降低环境差异带来的维护成本。
AI 智能体应用层 (Agent)
Agent 异构数据网格关联
在独立大语言模型之外,打通了丰富的外部企业环境动态上下文。
- 结构化关联:支持对话意图识别并直接向 MySQL/Postgres 等关系型数据源发起查询和数据钻取。
- 外部能力联动:通过 MCP 与插件体系,将企业内部接口、工单流、审批流等能力接入到 Agent 执行链路中。
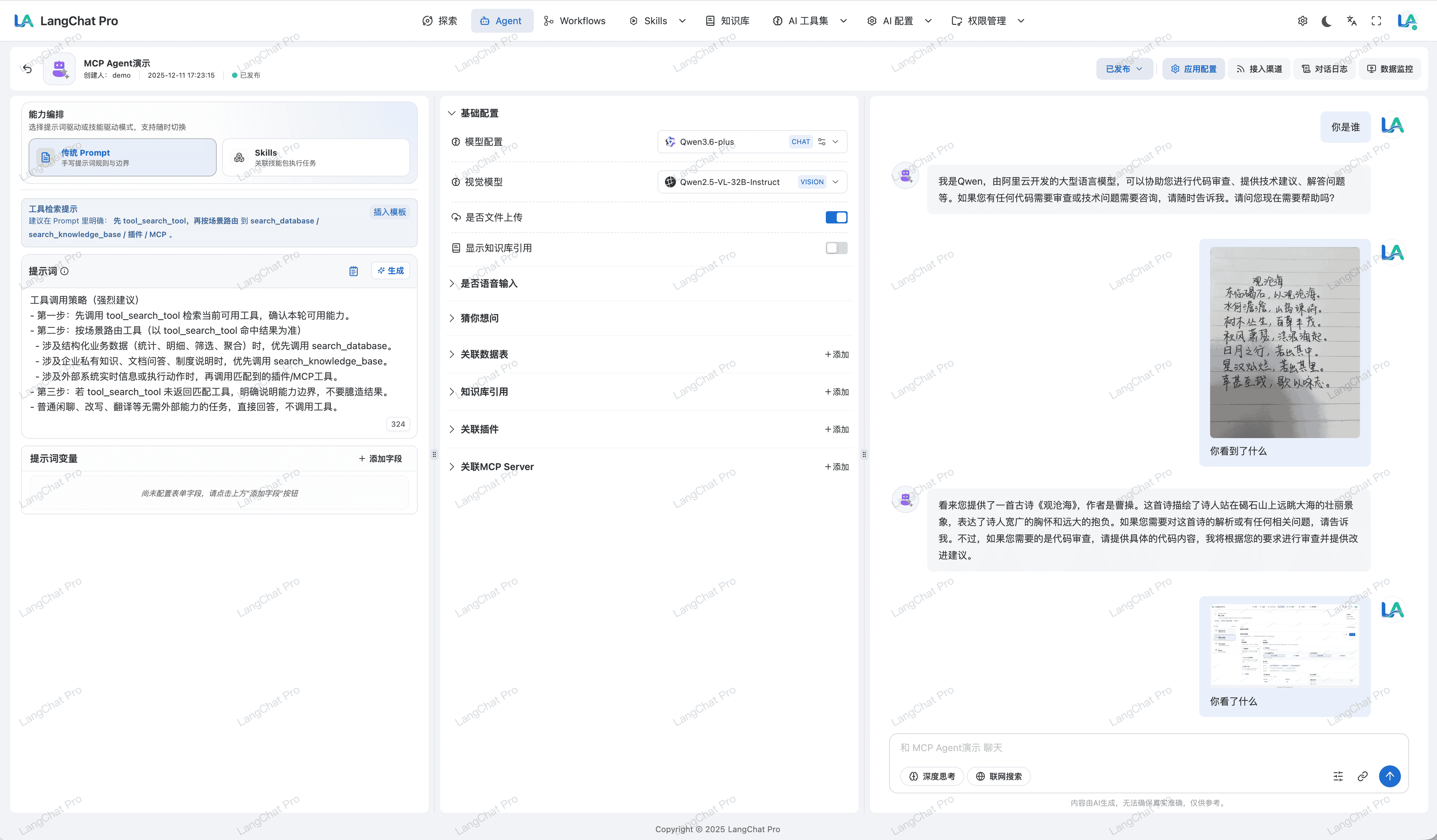
Agent ToolSearchTool 动态工具路由
在 Agent 构建链路中,平台提供基于 tool_search_tool 的按需路由机制。
- 先检索后调用:先根据当前任务检索可用工具,再选择目标工具执行,避免无效的全量工具遍历。
- 统一能力入口:数据库检索、知识库检索、MCP 与插件工具可统一挂载到同一套推理链路中。
- 可配置可追踪:前端配置面板与提示词中补充了 SearchTool 使用建议,便于团队复用和排障。
Agent多渠道发布
支持将Agent应用快速发布到API、企业微信、钉钉机器人、飞书机器人、公众号。
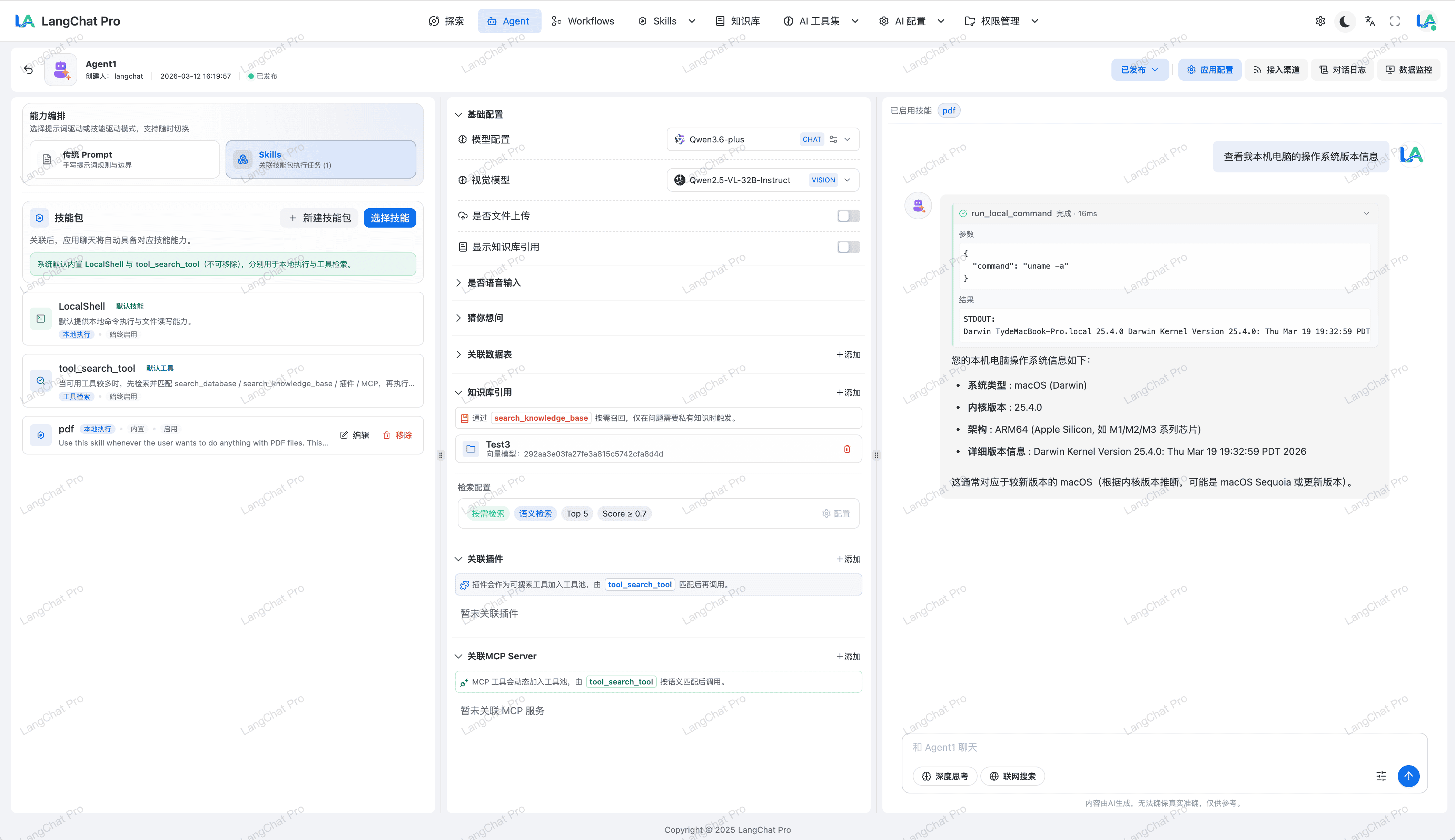
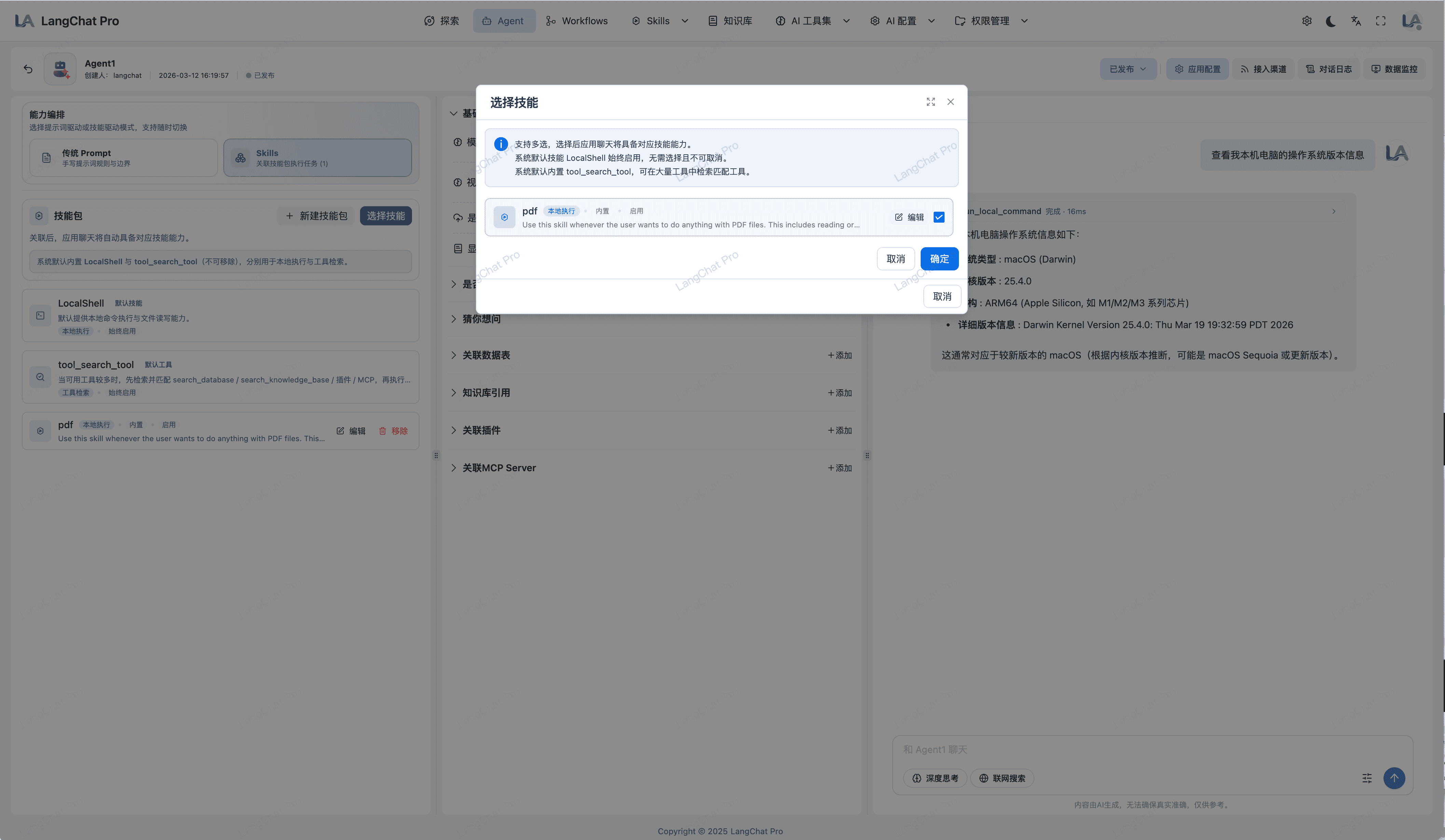
Skills动态挂载
支持单智能体快速挂载多个 Skills,实现多能力组合。默认绑定本地LocalShell技能,快速执行本地Shell命令。
Skills 能力层 (Skills)
Skills 能力接入与复用
平台将 Skills 作为可复用能力单元,支持在 Agent 与 Workflow 中按场景进行组合挂载。
- 多 Skill 关联:单个 Agent 或工作流节点可关联多个 Skills,覆盖数据处理、内容生成、外部系统调用等任务。
- 本地与沙箱协同:支持本地技能与沙箱技能协同调用,兼顾执行效率与隔离要求。
- 配置持久化:技能关联字段与默认能力提示可持久化,便于版本迭代与团队共建。
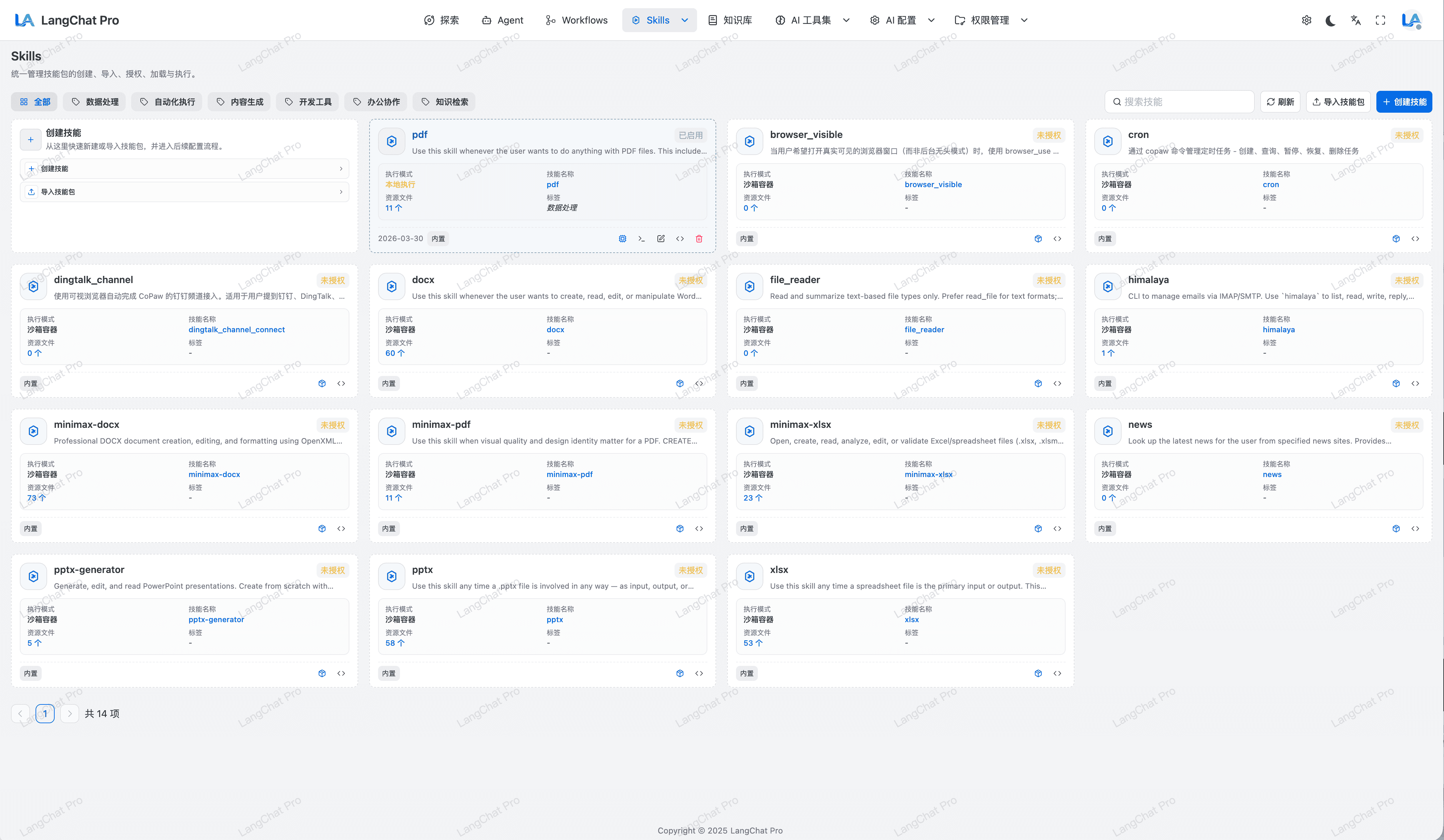
Skills 运行模式:本地 Shell + Sandbox
Skills 支持两种运行模式,可按任务类型选择执行环境。
- 本地 Shell 运行:适合本地资源可直接访问的任务,调试反馈更快。
- Sandbox 运行:适合隔离执行与受控资源访问场景,降低宿主环境风险。
- 自动绑定容器:支持根据技能配置自动绑定容器运行环境,减少手工运维步骤。
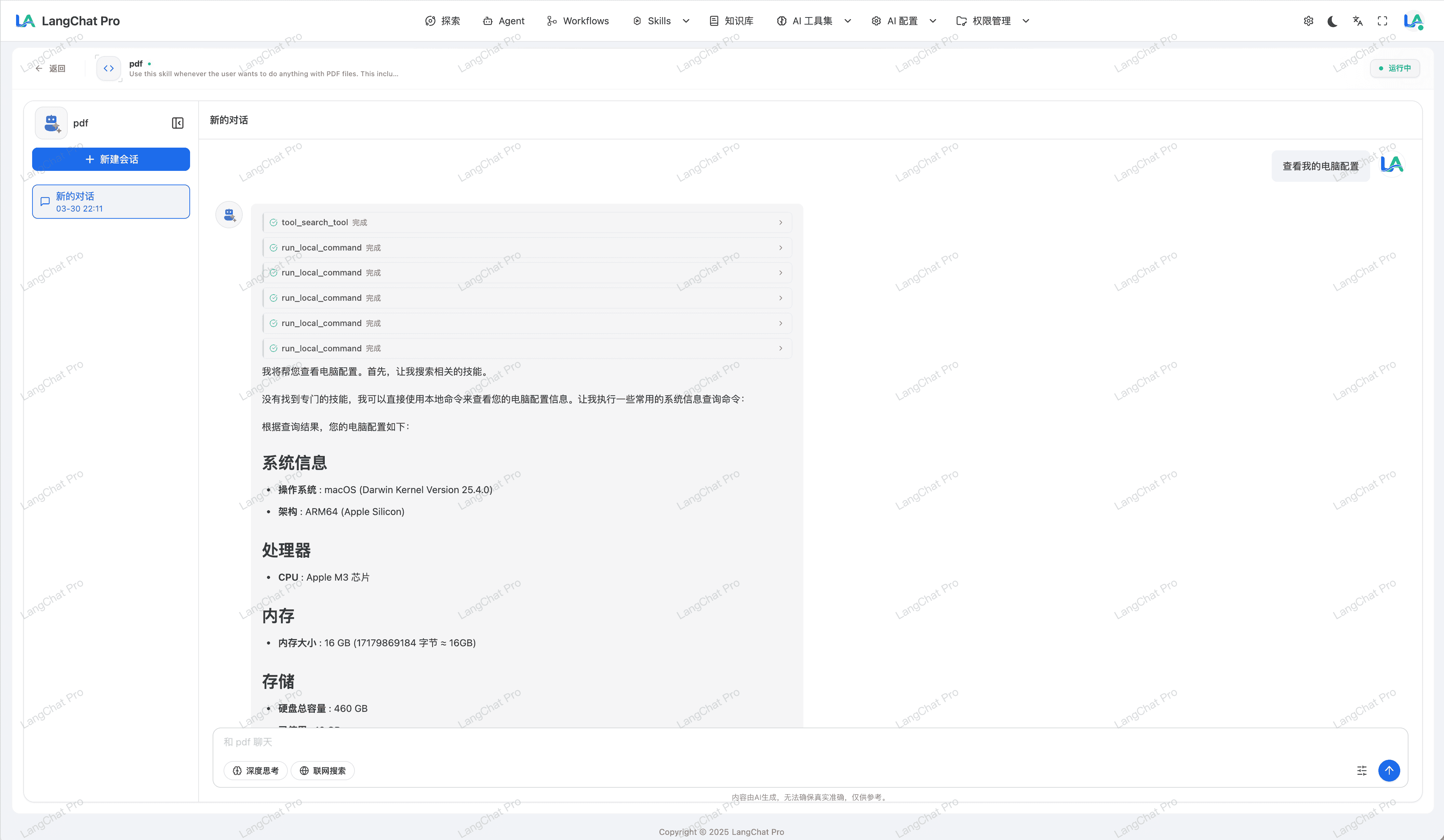
Sandbox 文件导出与批量下载
针对容器内产物交付,提供可直接面向业务使用的导出能力。
- 容器文件导出:支持将 Sandbox 内生成文件导出到外部可访问目录。
- 文件夹批量下载:支持按文件夹打包批量下载,便于一次性获取完整结果集。
- 适配交付场景:适合报告生成、代码产物、数据清洗结果等批量交付需求。
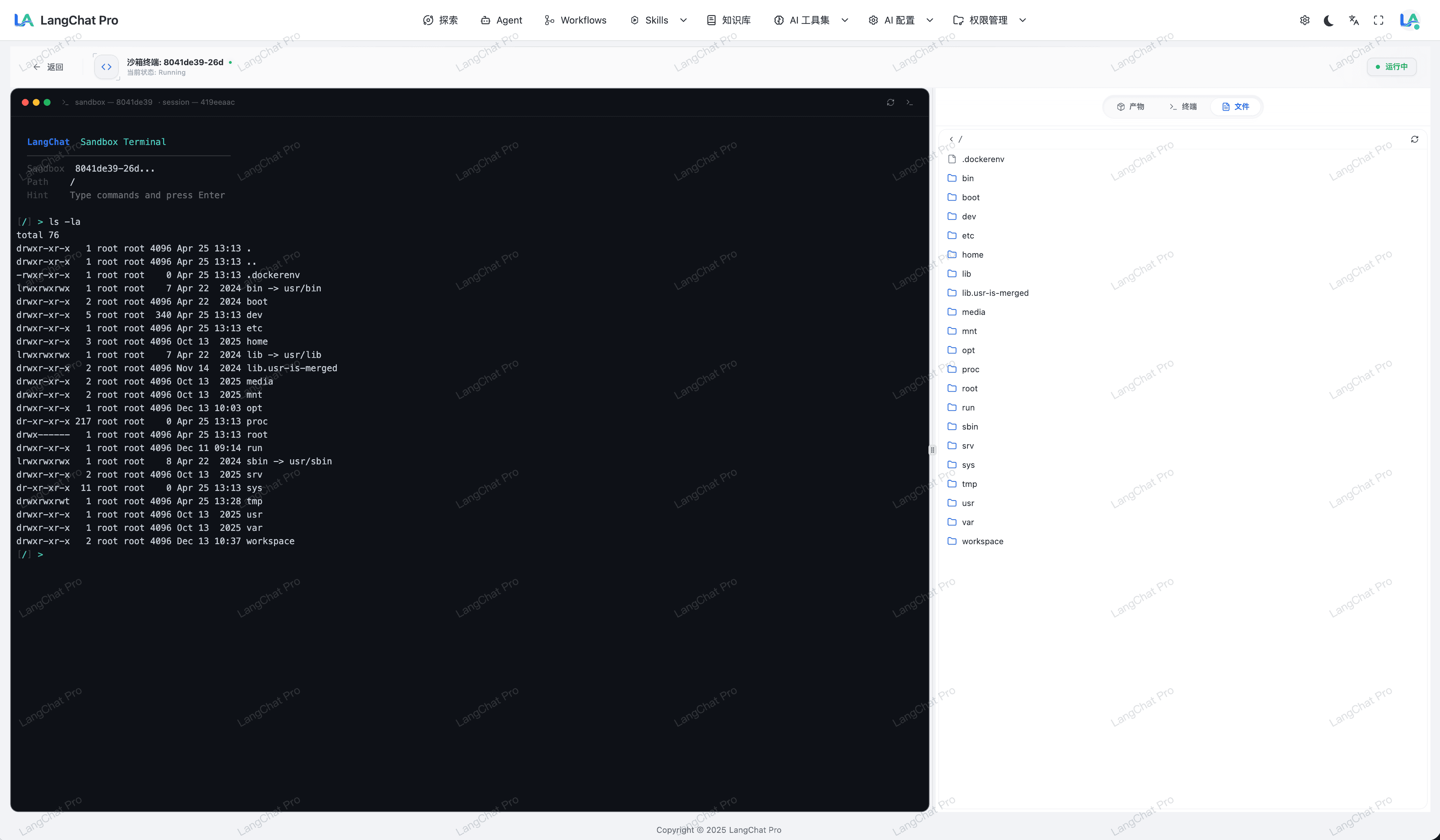
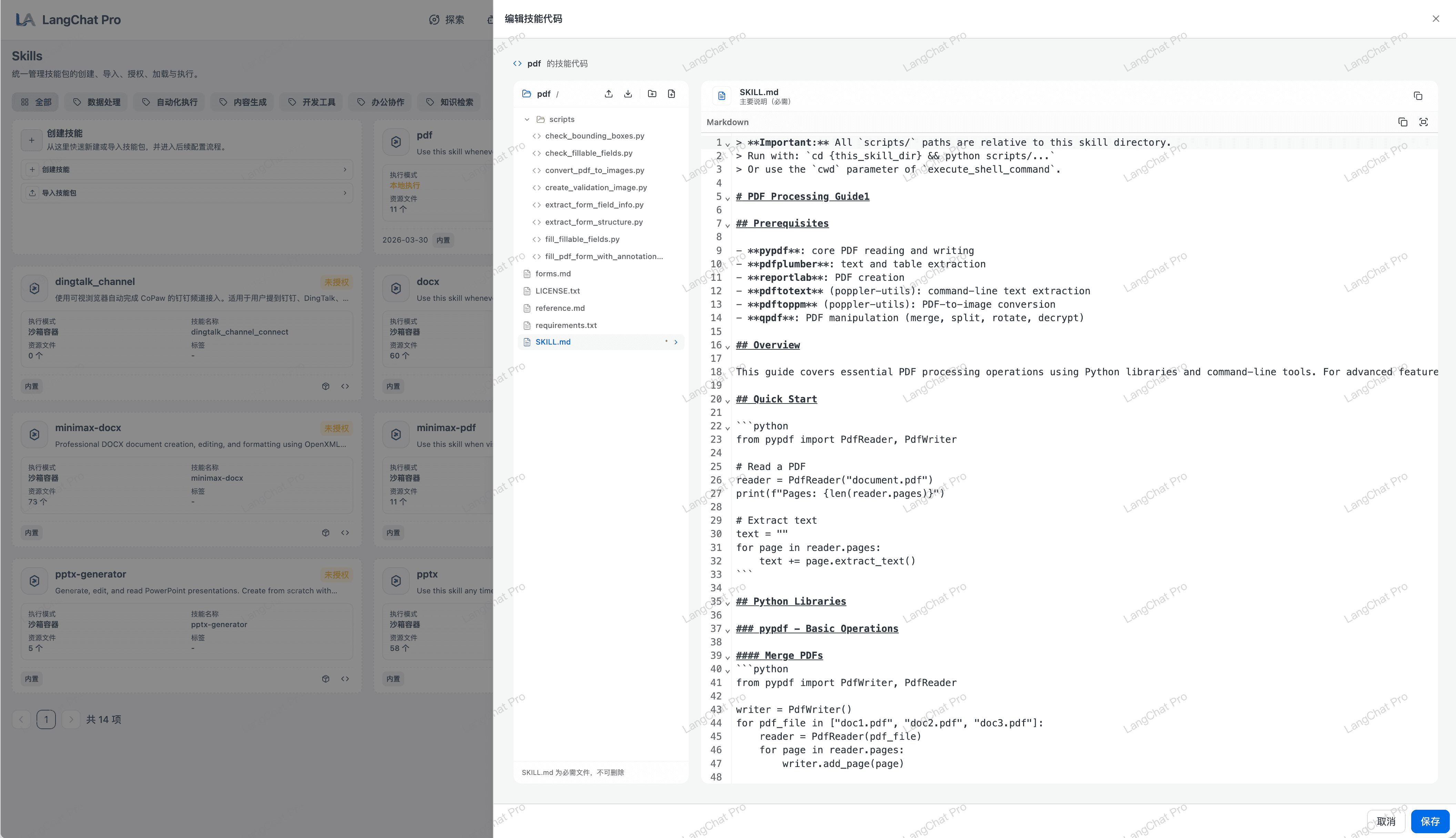
Skills 包管理与在线编辑
平台支持直接在界面维护 Skills 数据,降低维护门槛。
- 在线编辑技能包:支持在线维护技能包元数据、执行配置与说明文档。
- ZIP 技能包导入:支持上传并解析 ZIP 技能包,完成结构化导入。
- 标准化复用:导入后的技能包可统一管理、复用与版本迭代。
知识应用层 (Knowledge)
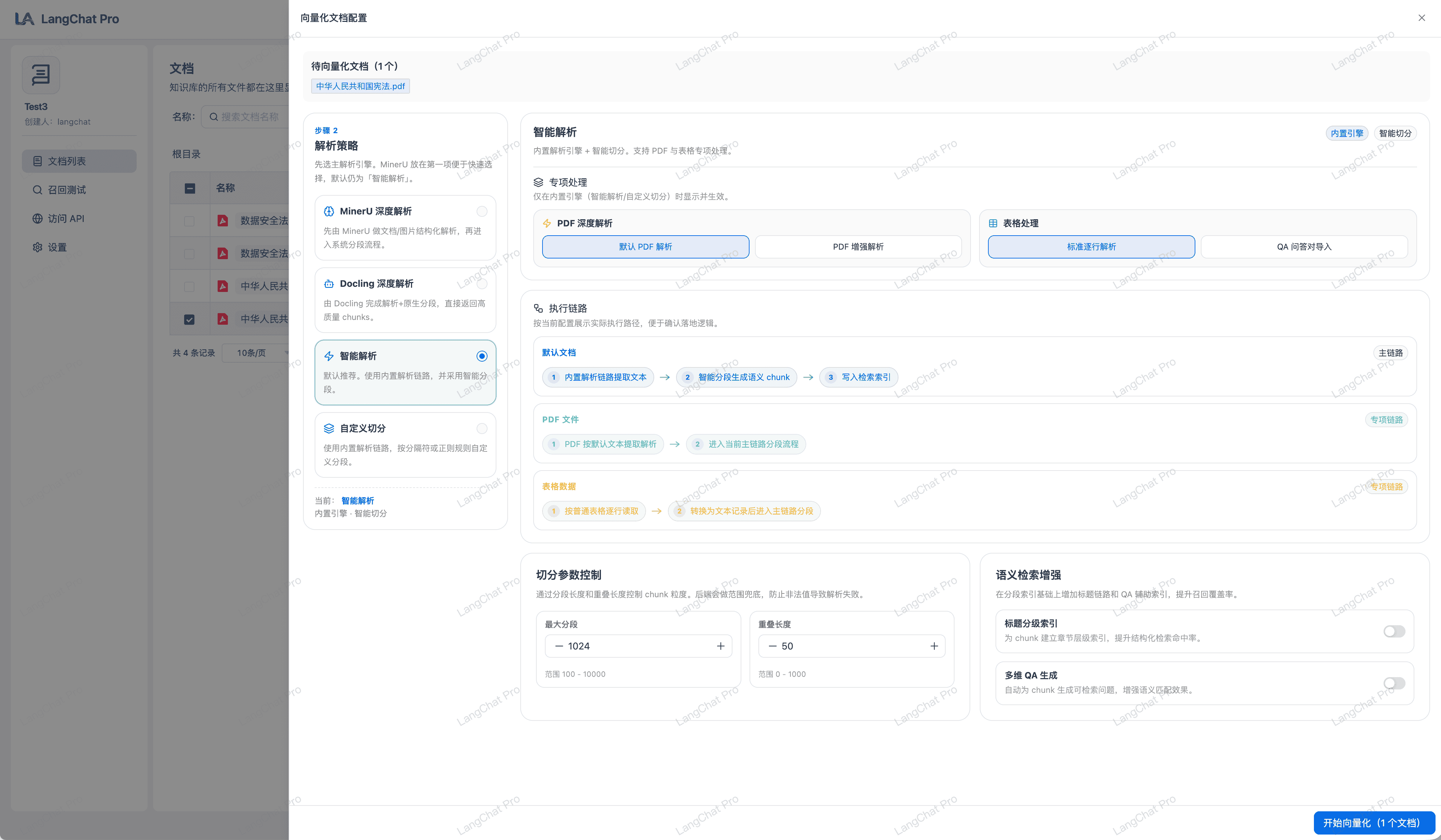
向量化文档配置:四种解析与拆分模式
知识库入库提供四种可切换模式,用于覆盖不同文档质量与业务场景。
- MinerU 深度解析:先完成文档/图片结构化解析,再进入系统分段流程,适合版式复杂的 PDF 场景。
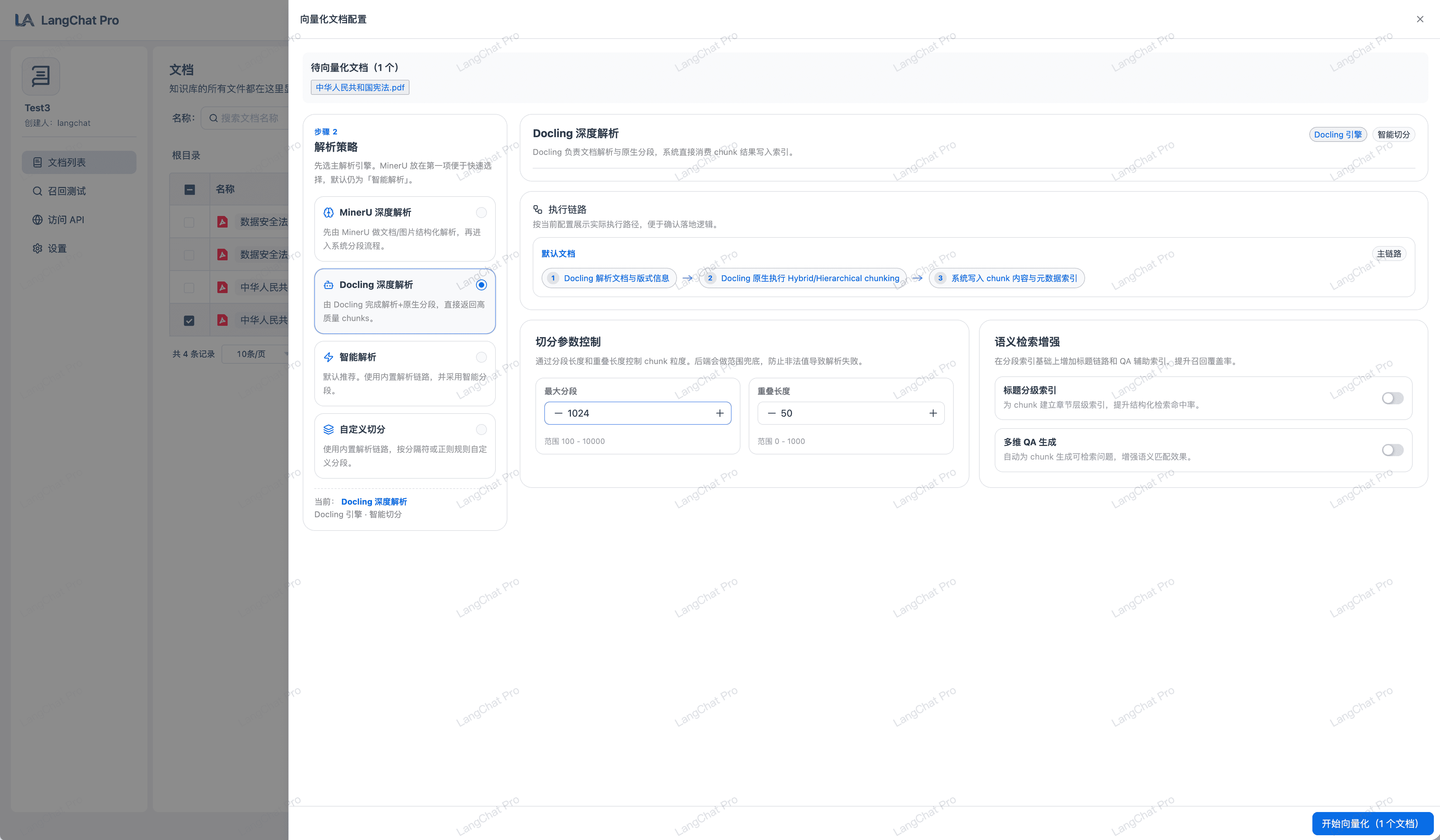
- Docling 深度解析:由 Docling 完成解析与原生分段,直接输出高质量 chunks,减少人工清洗步骤。
- 智能解析(推荐):采用“内置解析引擎 + 智能切分”,并支持 PDF、表格的专项处理策略。
- 自定义切分:先走内置解析链路,再按分隔符或正则规则执行自定义切分。
执行链路、分段参数与检索增强
向量化配置页面会展示当前策略对应的执行链路,便于确认最终入库路径。
- 默认主链路:内置解析链路提取文本 -> 智能分段生成语义 chunk -> 写入检索索引。
- PDF 专项链路:先按 PDF 专项策略提取文本,再进入主链路分段流程。
- 表格专项链路:先按表格策略读取并转为文本记录,再进入主链路分段。
- 切分参数控制:支持“最大片段长度(100-10000)”与“重叠长度(0-1000)”配置,用于平衡召回粒度与上下文连续性。
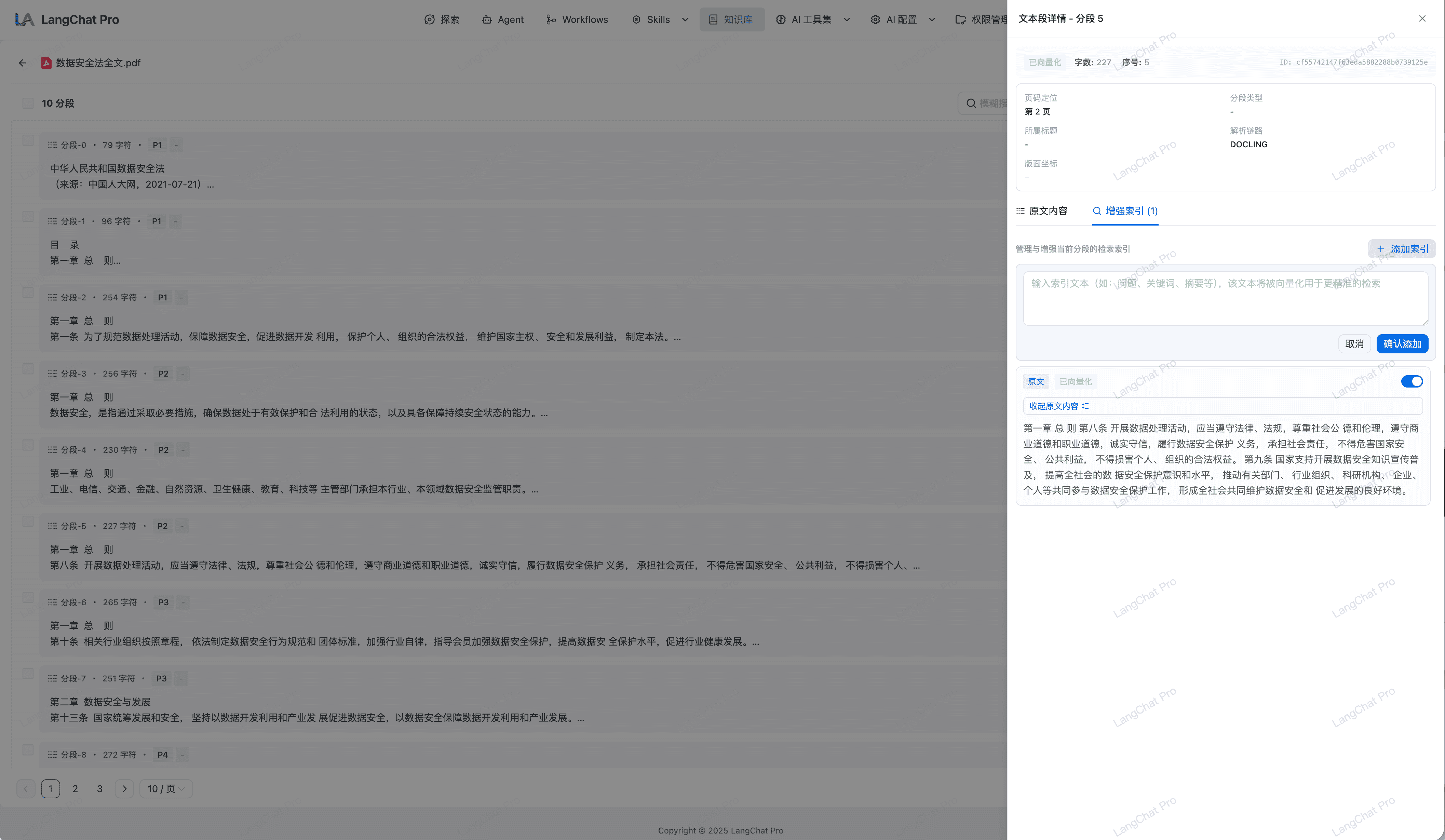
基于 RAG 的混合检索与召回优化
在入库完成后,知识库通过向量检索与关键词检索协同提升召回质量。
- 混合索引架构:结合 Elasticsearch / Milvus,统一支持语义相似度与 BM25 关键词召回。
- RRF 融合重排:通过倒数排名融合(RRF)合并多路检索结果,降低长尾术语漏召回和答非所问情况。
- 语义检索增强:支持“标题分级索引”和“多维 QA 生成”开关,提升结构化检索与问答命中率。
动态编排与多模态扩展层 Workflows
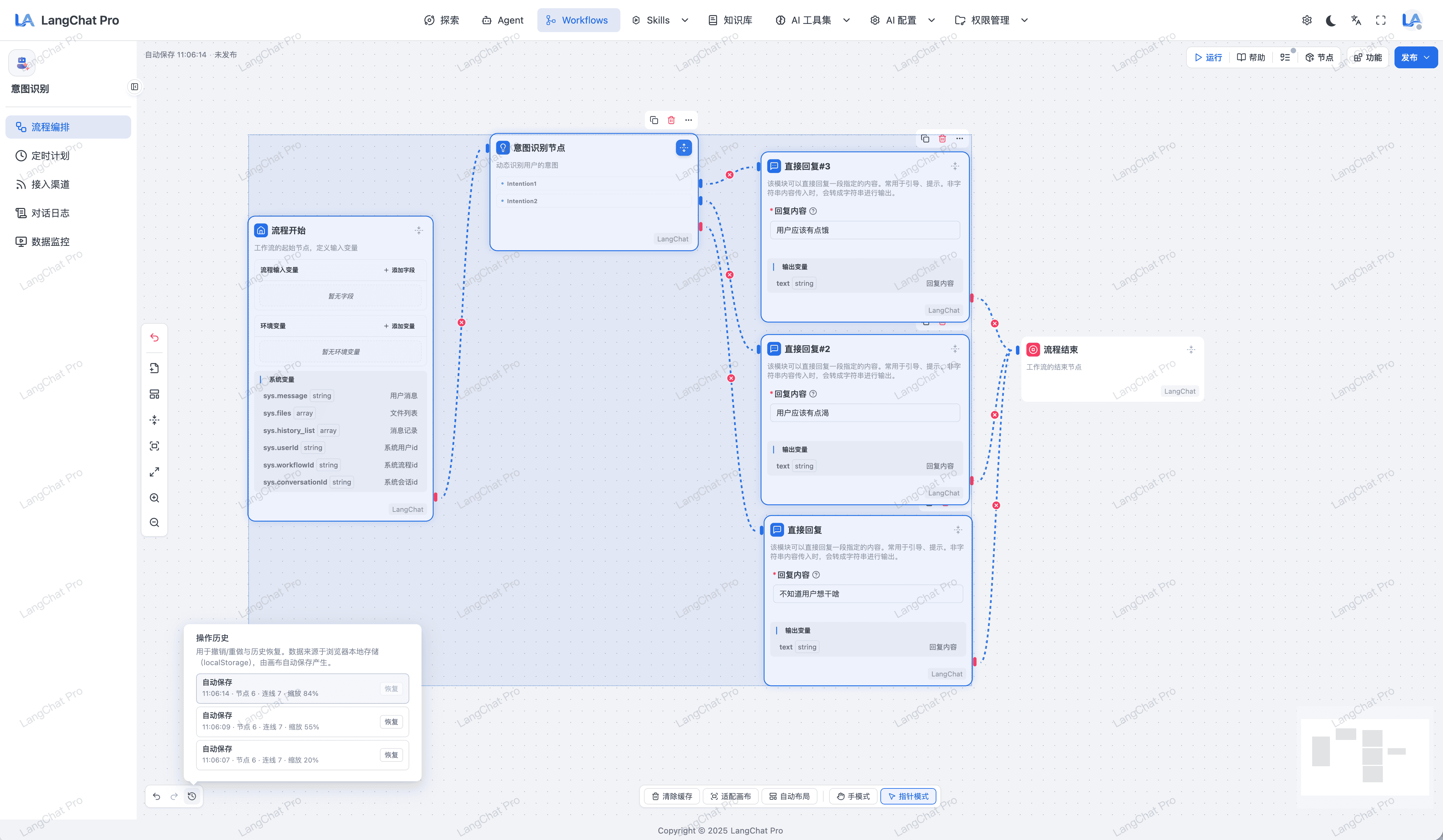
专业工作流画布UI交互体验
专业且美观的工作流画布,支持拖拽、连线、节点参数配置、全局参数配置、执行步骤追溯(Tracing)面板。
- 操作历史回溯:基于浏览器存储记录每次操作记录,快速回滚到某个历史操作
- 智能化排版:针对复杂的画布节点可以智能排版,让画布节点排列有序
- 多种操作模式:支持画布切换指针模式,快速框选多个节点同时拖拽
- 节点折叠排版:支持全量折叠节点,快速预览节点设计
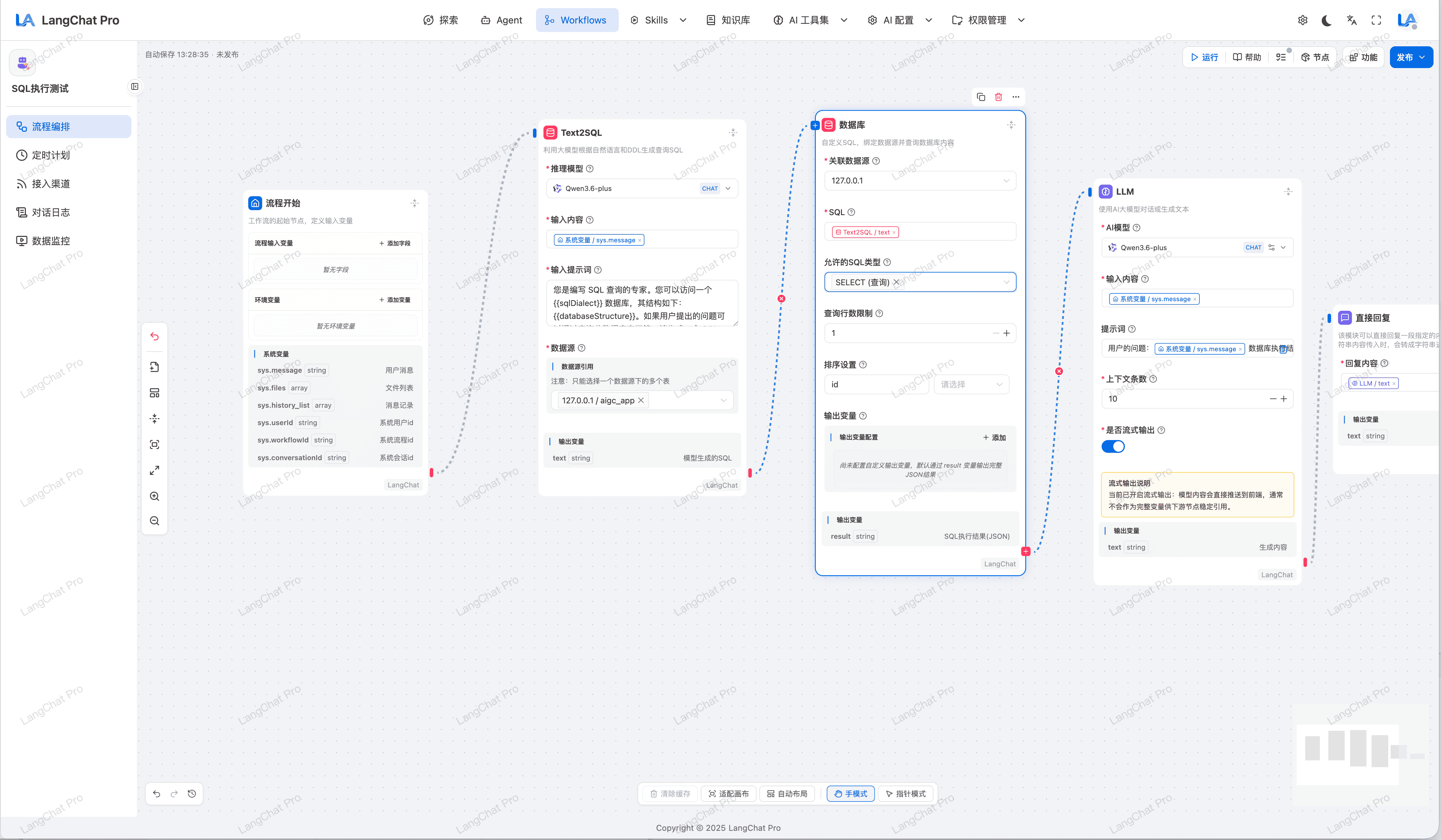
工作流动态低代码编排引擎
采用 Java 强类型轻量级状态机控制调度,为逻辑复杂的长线程任务或 AI 应用提供了可视化的托拽拼装环境。
- 可视化画布:基于定制化 VueFlow 面板,一目了然实现节点间的线状数据依赖、全局上下文参数流动以及执行步骤追溯 (Tracing) 面板。
- 增强流程控制原语:IF / Loop / Intention 节点支持单 Case 多条件组合,支持
AND/OR逻辑,并支持循环终止条件配置。 - ToolSearchTool 动态路由:在工作流中可通过
tool_search_tool先检索候选工具,再按需调用目标工具,减少无效调用链路。
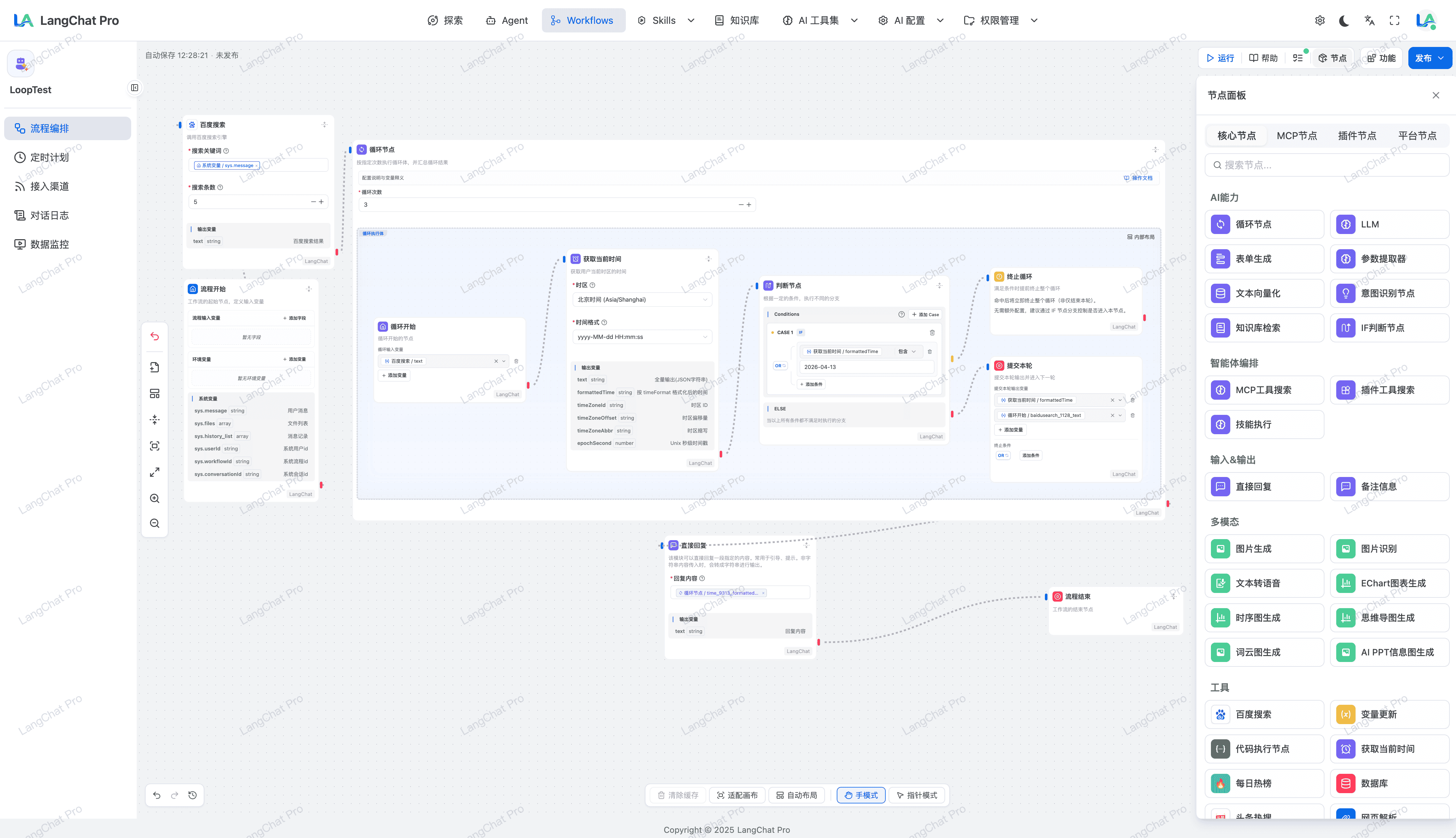
智能路由判断节点
支持IF/Intention/Loop等动态路由节点,快速构建复杂工作流。
- IF 节点:支持单 Case 多条件组合,支持
AND/OR逻辑,并支持循环终止条件配置。 - Intention 节点:只是单意图配置多个示例,可快速构建多意图判断逻辑。
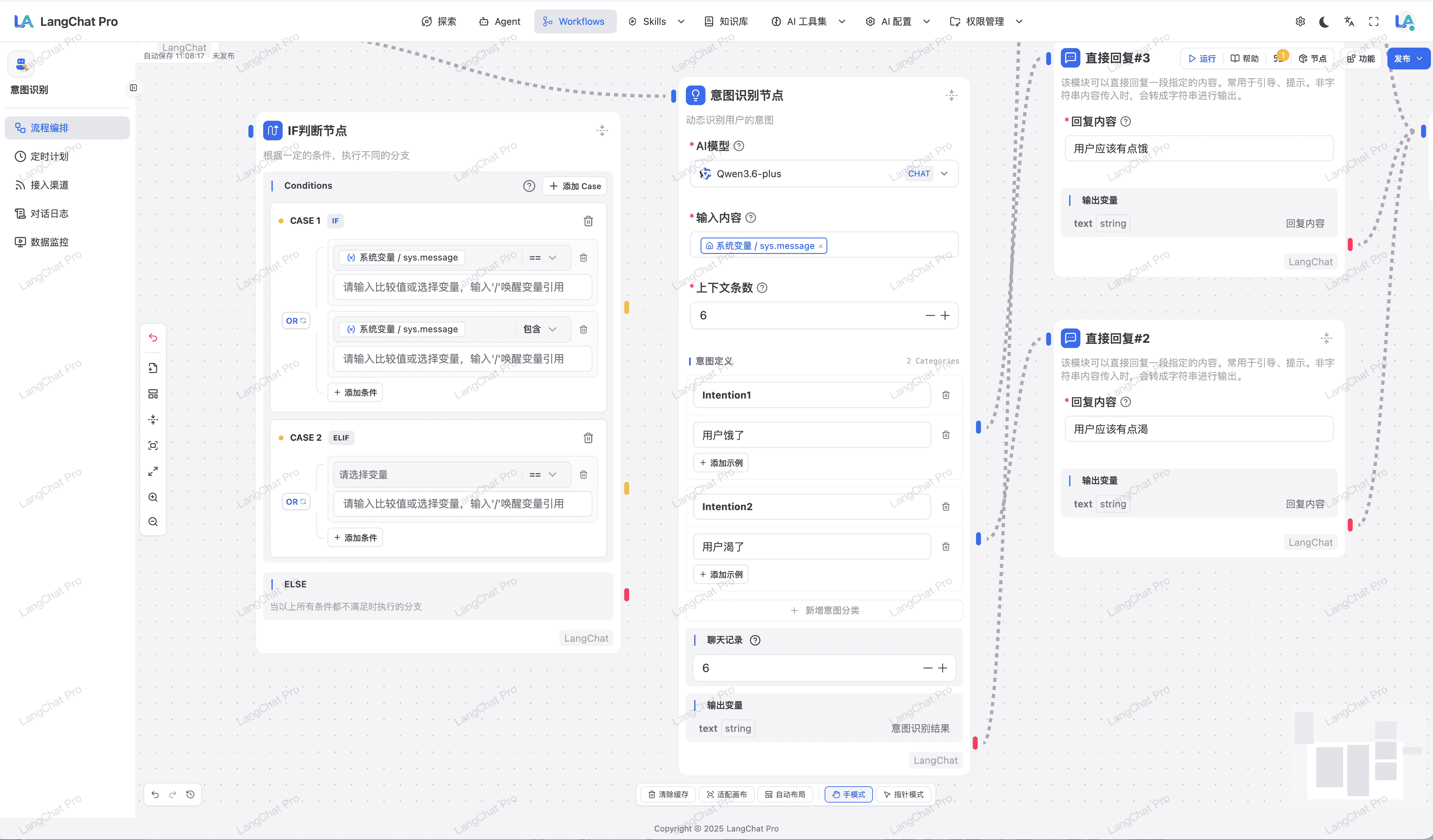
Loop循环节点构建子流程
利用Loop循环节点构建子流程,实现复杂逻辑控制。
- Loop 节点:支持单 Case 多条件组合,支持
AND/OR逻辑,并支持循环终止条件配置。 - 子流程构建:支持子流程构建,实现复杂逻辑控制。
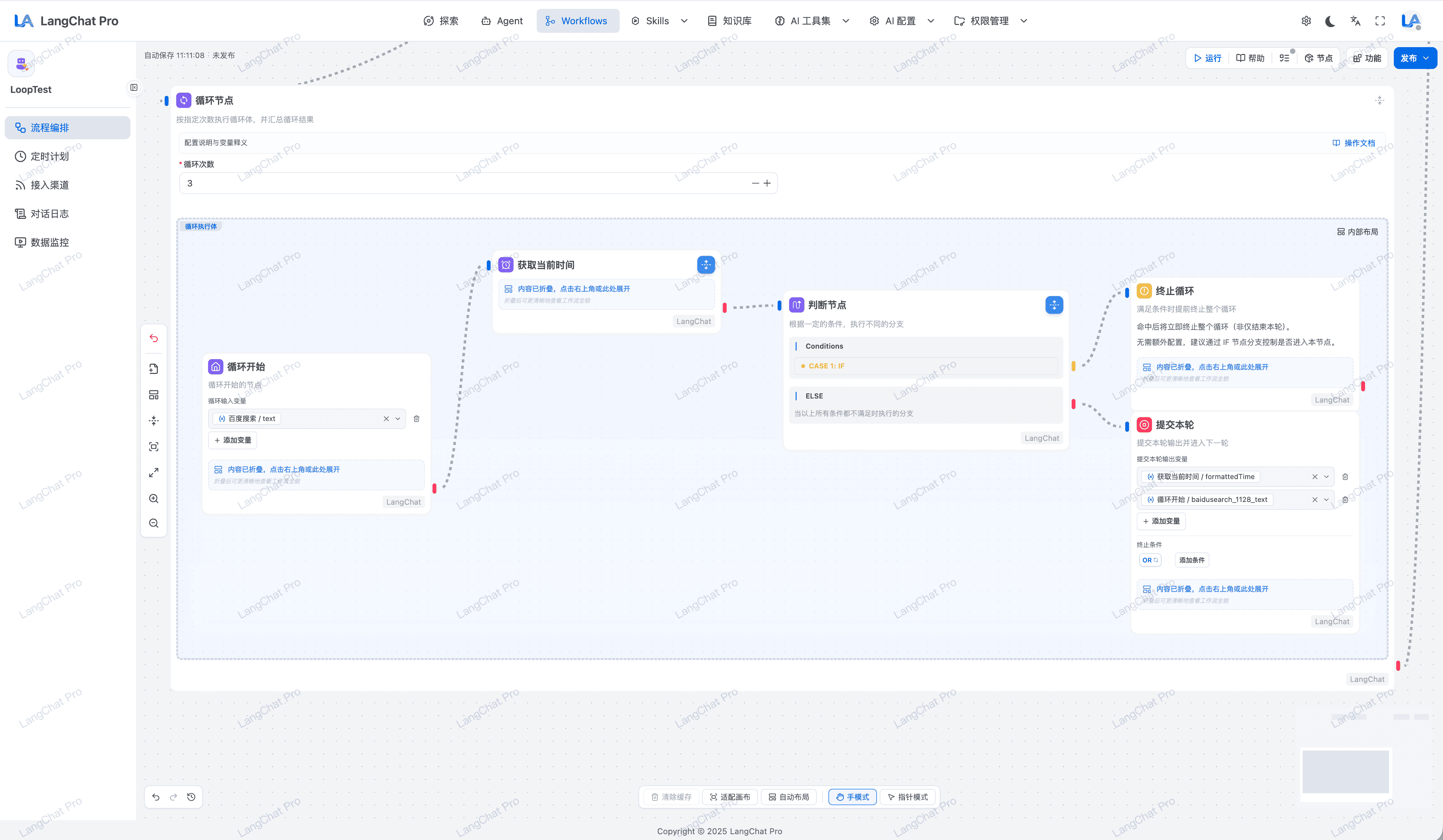
模型动态构建
模型动态构建,支持任意模型接入,实现模型动态构建与调用。
动态构建FunctionCall插件
LangChatPro支持将一个RestFul接口适配为LangChatPro的FunctionCall插件,实现Agent动态关联和自动化调用。
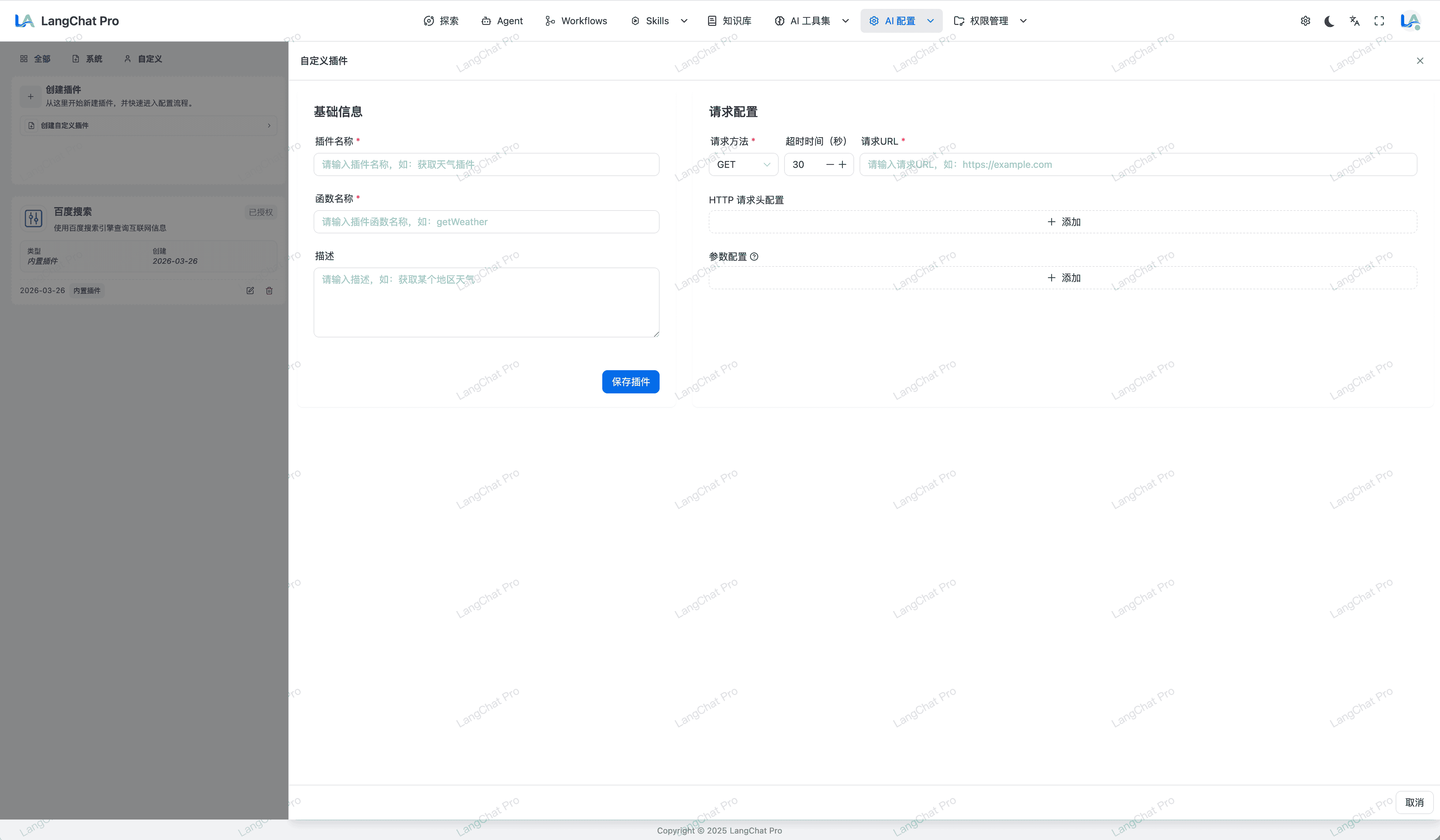
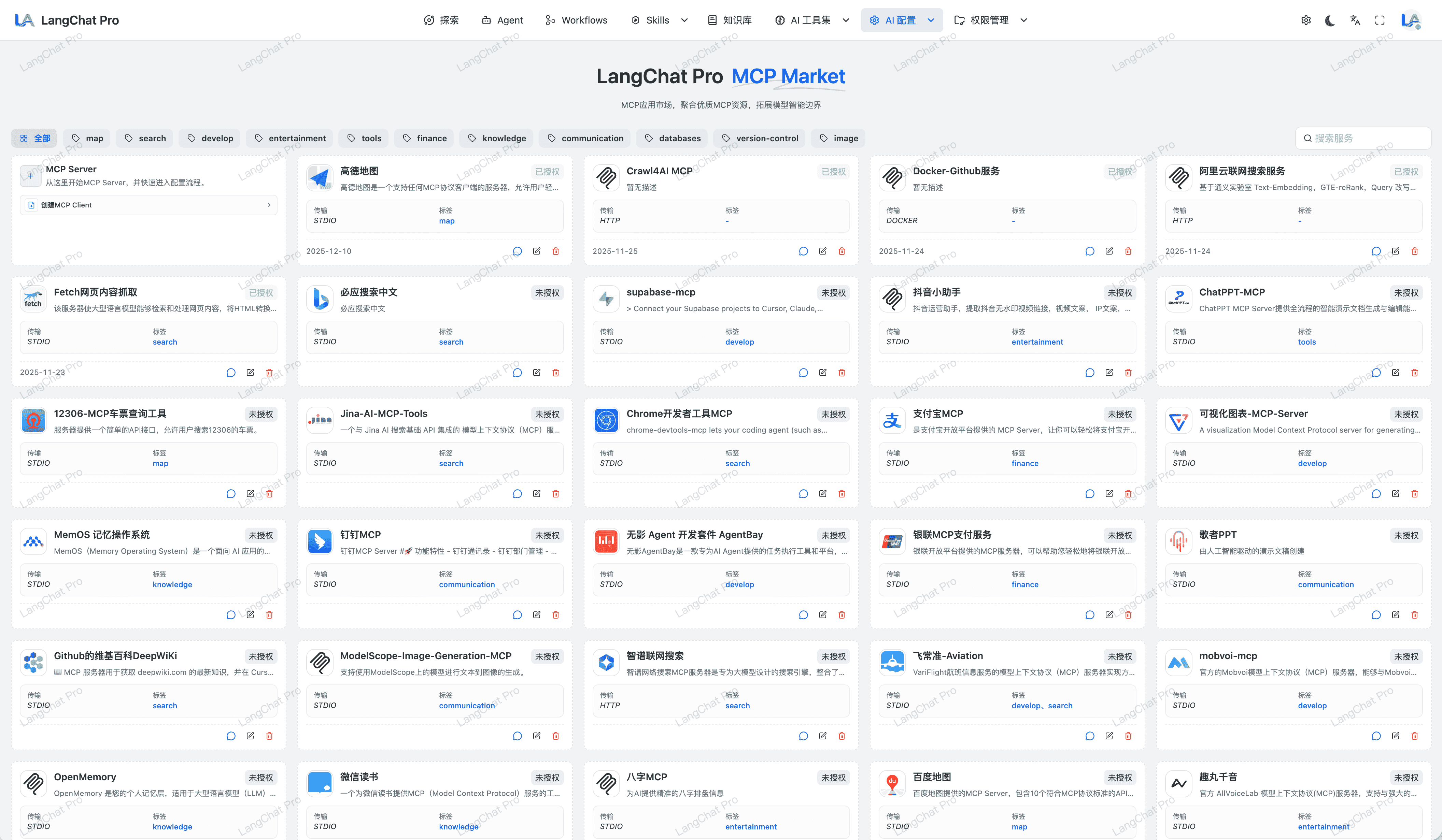
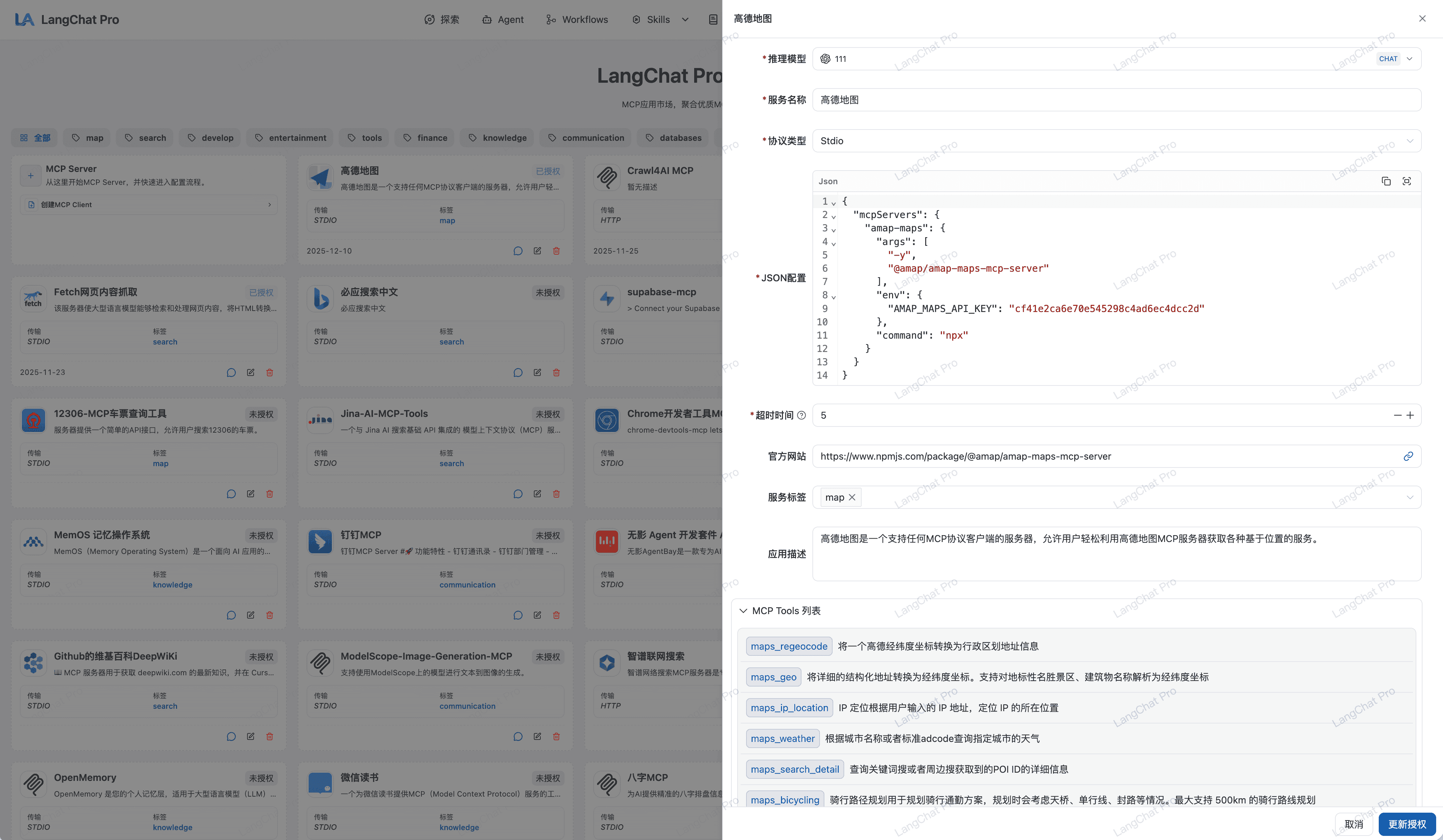
MCP协议接入
全面接入与拥抱大模型标准工具调用协议 (MCP) 与自研本地函数执行网关体系。
- 内置MCP 200+:完全兼容 HTTP SSE / Stdio 乃至 Docker 内联等各大环境通讯方案。
- @Mcp注解:提供简单的Java注解快速将函数暴露为Java MCP服务。
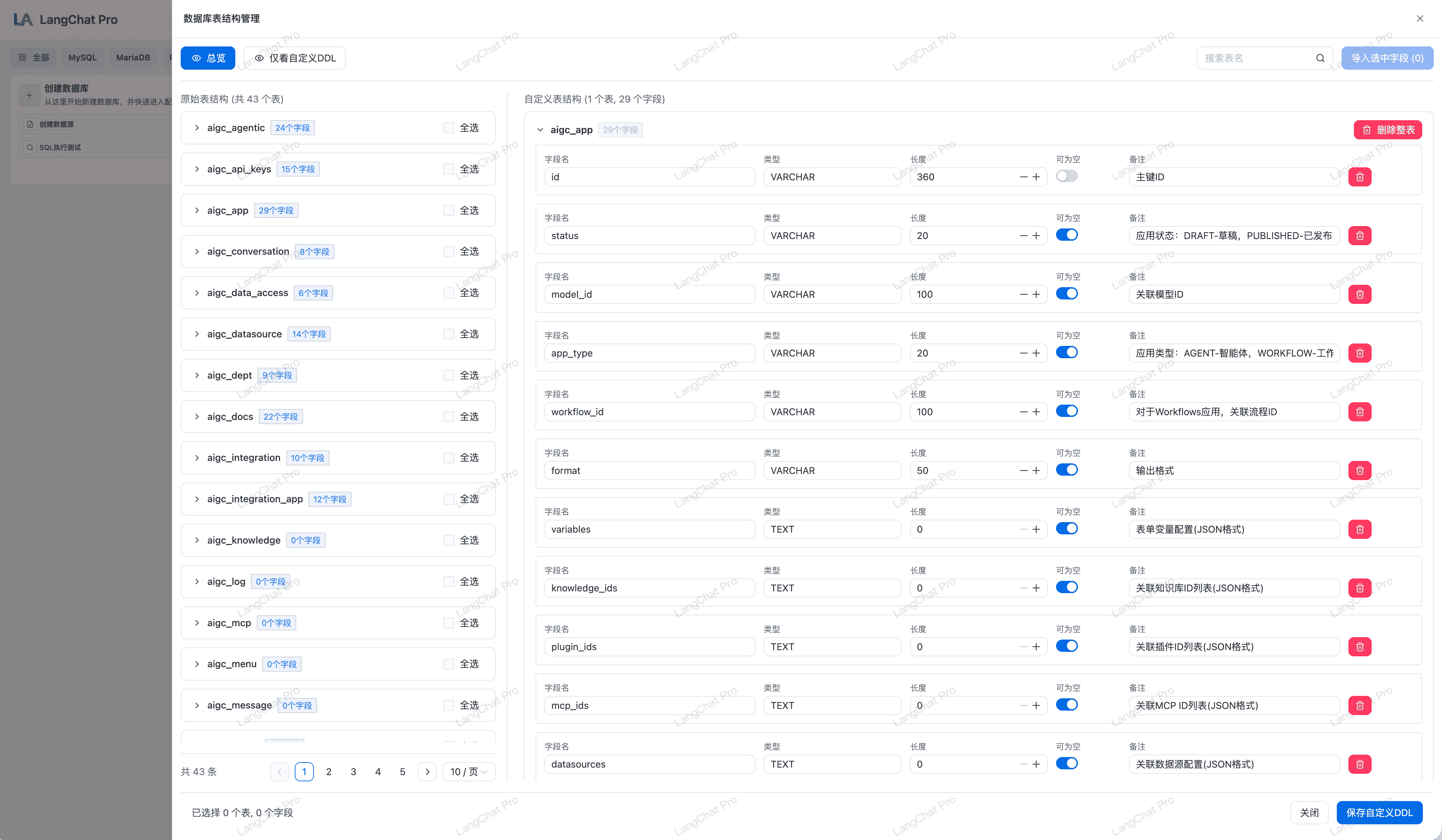
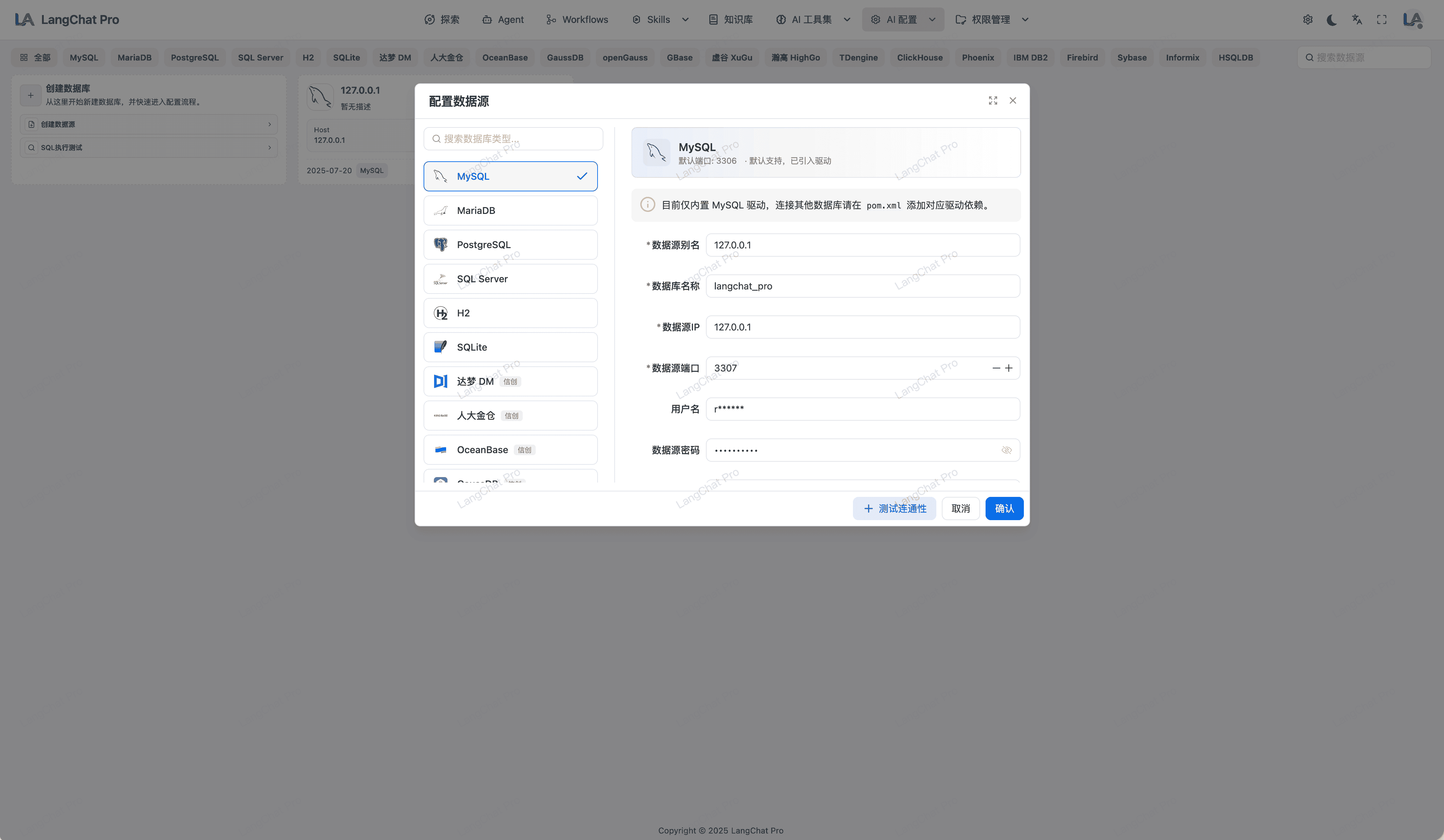
Text2SQL
针对强数据驱动的高净值运营类客户的开创性 SQL 自构建底座机制方案。
- 业务语言与物理引擎架构映射桥梁:颠覆行业原生只有纯英文表结构的查询痛点。首创支持自由附加的动态多维中文标注(DDL增强结构图册),由浅入深教育大语言模型了解字段业务背景。
- 原子级权限控制:系统默认仅开放
SELECT只读权限。管理员可以根据业务需求,在前端界面灵活配置允许执行的 SQL 类型(如INSERT、UPDATE)。 - 首关键字实时比对:后端在执行前会通过
jsqlparser对 SQL 语句进行 AST(抽象语法树)解析,精准提取首个指令关键字。如果检测到DROP、TRUNCATE、DELETE等危险指令,系统将直接抛出异常并终止节点运行,确保核心数据的绝对安全。
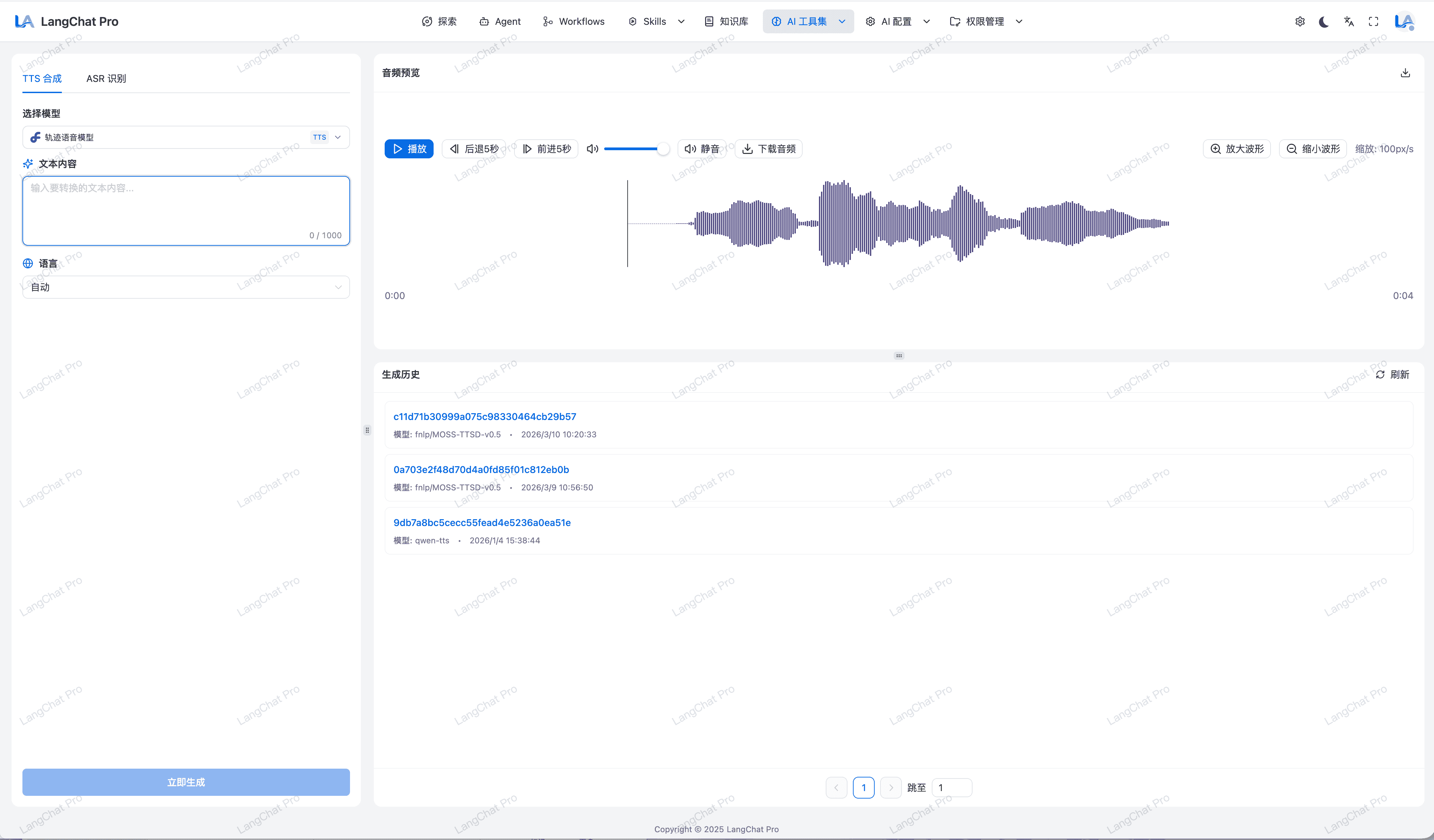
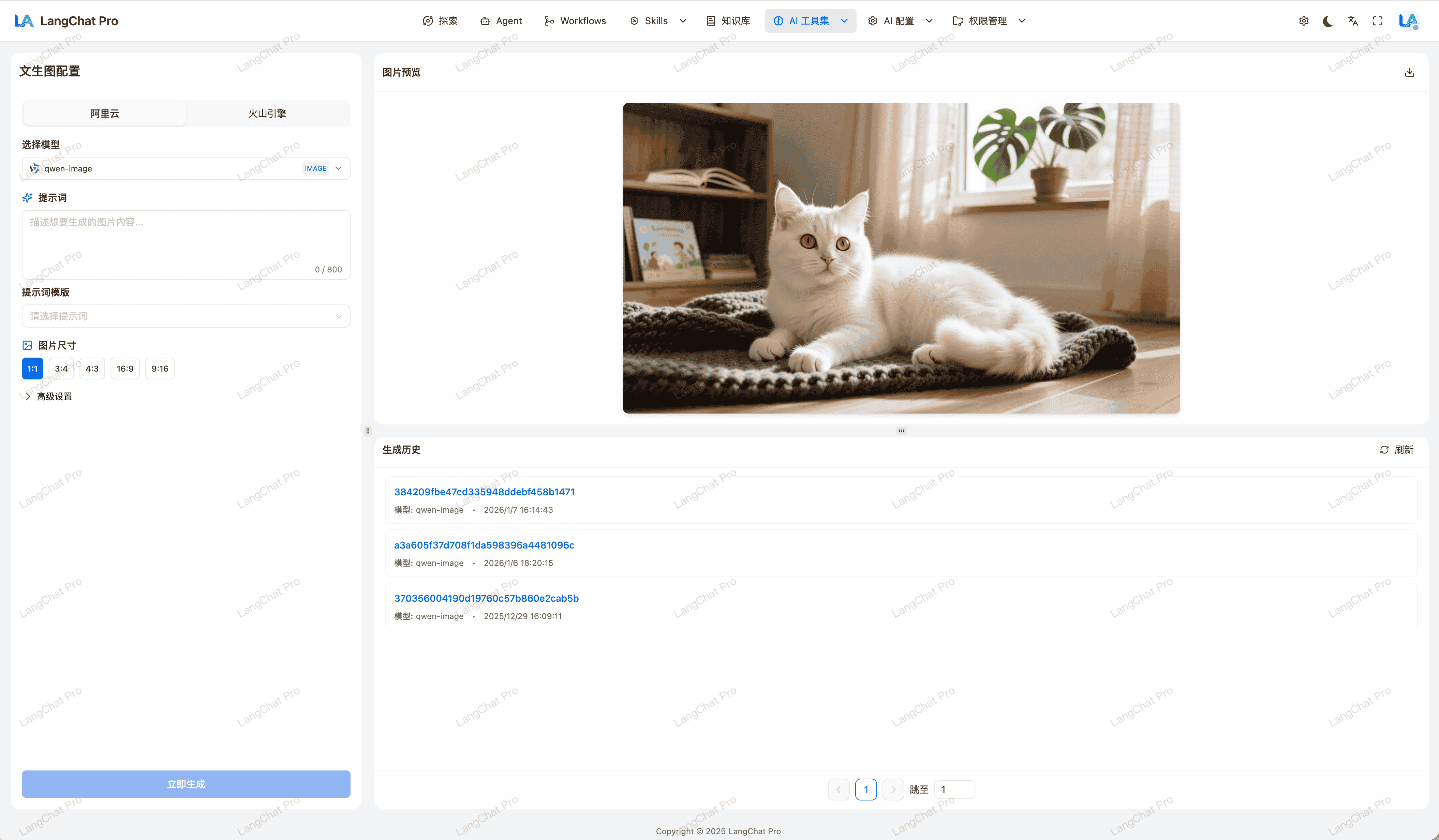
多模态
提供专业的多模态功能页面,快速了解多模态能力
- 文生图:利用视觉模型将文本转成图片
- 图生文:利用视觉模型将图片转成文本
- TTS/ASR:利用语音模型将文本转成语音,将语音转成文本
- 视频合成:利用视觉模型将视频转成图片
专业写作功能插件
LangChatPro针对写作场景封装了专业的AI富文本编辑器,支持PDF、Word、Markdown、Excel格式文件导出。
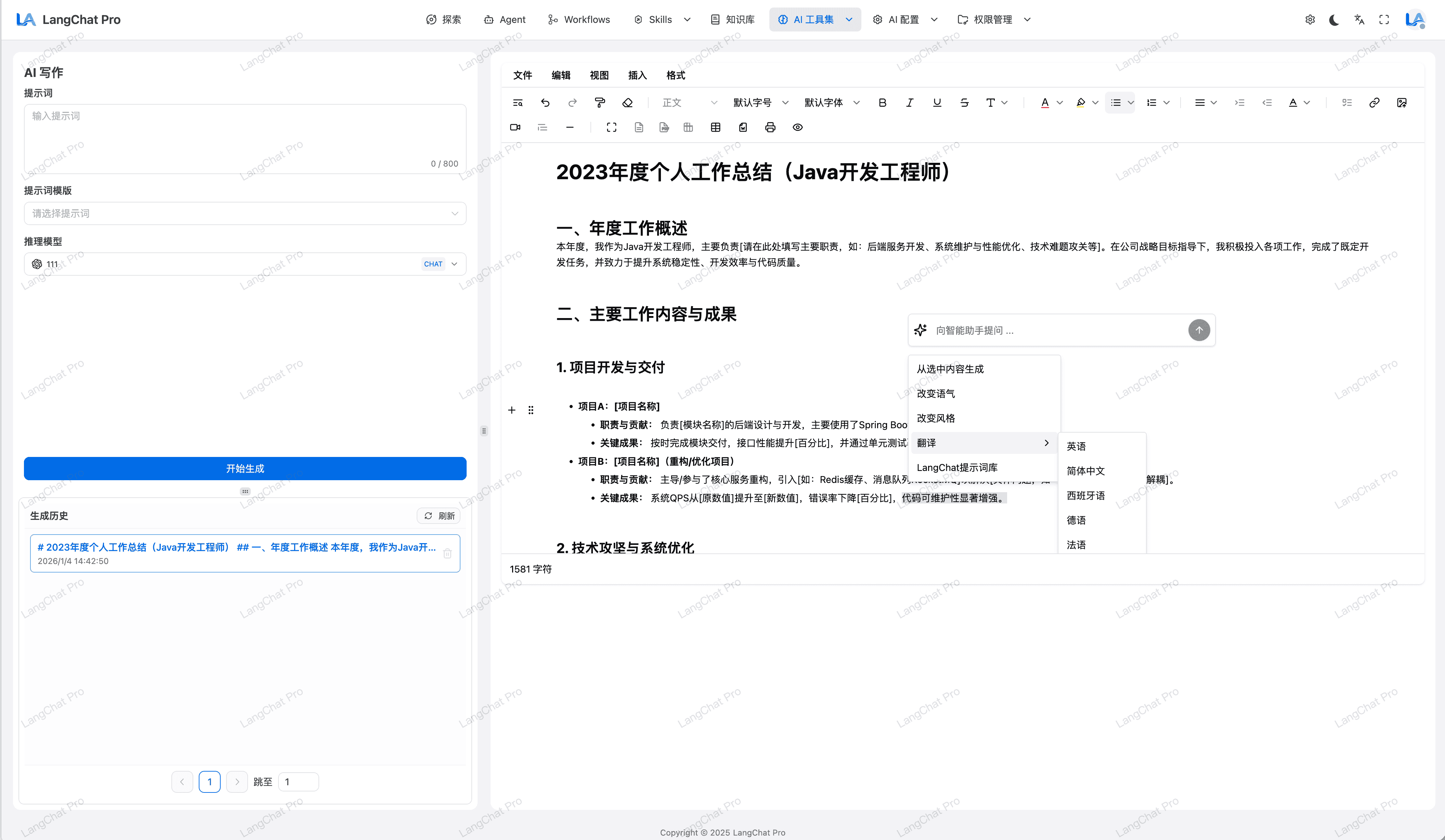
敏感词过滤
提供敏感词过滤系统,对敏感词进行过滤,保证数据安全。
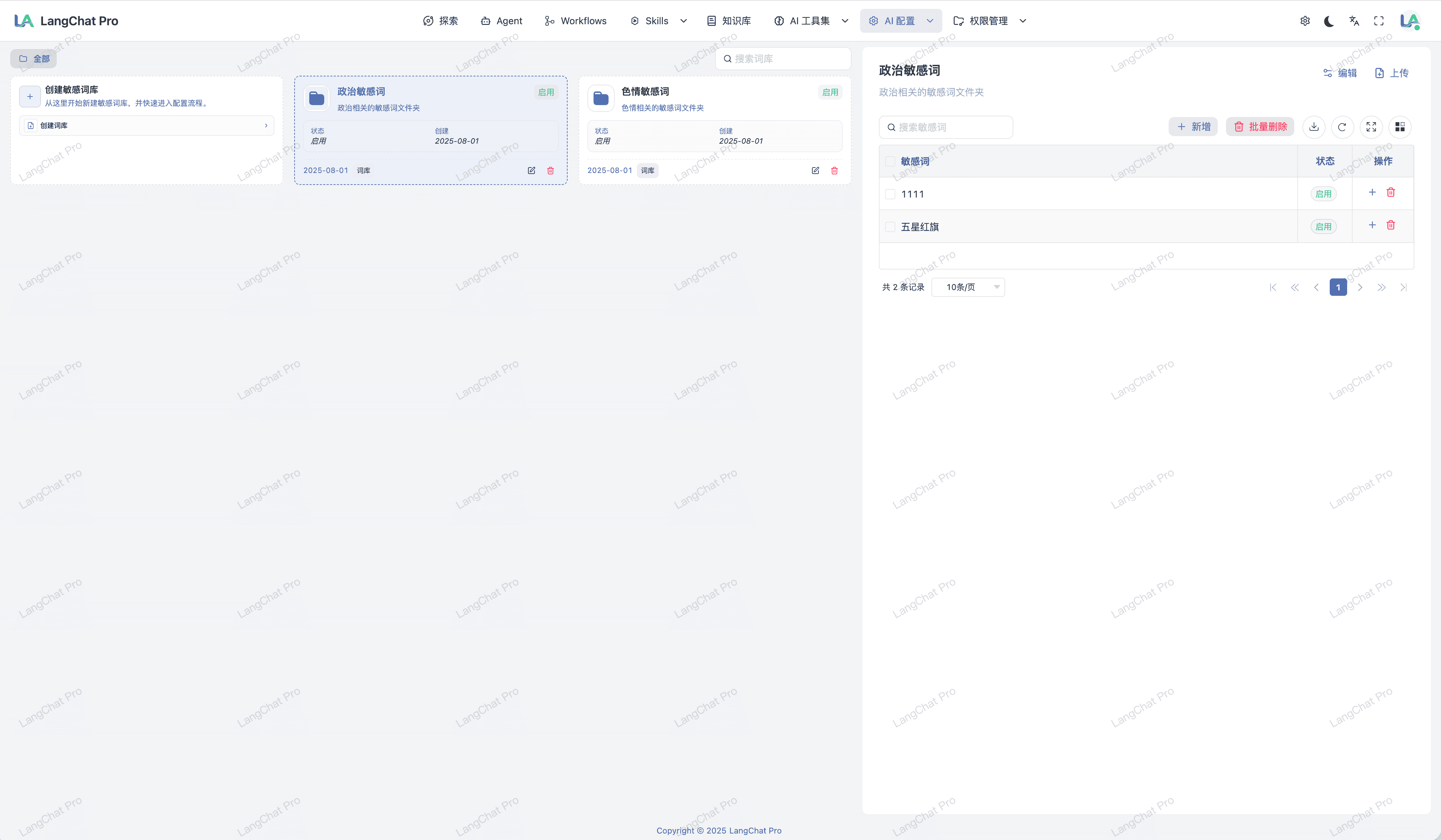
模型调用监控体系
针对平台所有模型调用链路,构建全生命周期的模型费用监控体系。
RBAC权限体系
提供标准的RBAC权限管理体系,提供用户、角色、菜单、日志等权限管理。
商业协议与授权边界红线规避细则
敬请采购 LangChat Pro 平台的客户务必审慎遵循平台针对企业知识产权底线维护及安全利用行为防范建立的保障防线体系要求规则制度方案:
核心底线规定红线要求界限定义标尺:针对除自用服务企业之外面向向非定第三方机构流包转授权打包出售再营利化行为的(俗称二次买卖商用传播等侵犯所有权界定规则事件),被定义为平台严制打击的无效商用无授权法理行动!
核心授权范围定义解释界定及豁免责任界碑说明:
- 合规合度企业内部闭环流转授权法权界碑定义范畴说明(包含禁止):已签单确权认知的最终授权母版所属公司、企业机构(其中法律定义上并不额外隐性囊括其后续并购剥离的上下属等子公司名册单位人员)可不限生命线期限长度在完全自主内控封闭的生态业务大循环体系里进行自如随心修改调配。切忌在未经平台重新赋予资质名额的前提下私下进行源码交底及打包重转分发第三方或者越线申报软著知识产权法案;
- 关于承制系统及代建项目合法合规外发行为许可边界条款规范细则限定机制说明解释:如果您公司性质属 IT 技术研发或者信息化咨询交付团队身份购买使用了此类框架技术服务协议方案包、去履行自身承担的企业甲方或者独立外部客资团队委托代做实施开发的商业软硬集成研发建设应用及项目交付类合同承诺业务范畴时行为限定准则要求:乙方企业团队必须要提供给第三方甲主经过底层高维密码混编锁定和高纯封装之后的单体镜像打包或是封闭式无法读取逻辑源文件 jar。要是您被服务终端或下家必须强调明明白白索求这部分属于系统原架的最纯粹基础驱动内核运行架构底座源文件。麻烦您作为服务代办商一定需要再转交替此甲方机构按照商务采购政策规则去平台进行专门的新户授权购置及登记名册确权备案准入才符合规矩和底线要求框架!!!
- 维保和支援:签约白皮书客户自然享受工作流级别的研发响应及在线核心故障架构解答权限支持体系,工作时间范围内 8 小时必回复常规咨询指导建议方略协助方案模型、重灾故障崩溃场景支持专线最高层级 4 小时紧急下场干预保障承诺底线协议体系!
技术架构
| 技术类别 | 技术栈清单 |
|---|---|
| 前端平台环境 | 核心框架:Vue 3.4+(Composition API) |
| 语言环境:TypeScript 5.0+、Node.js v22 LTS | |
| UI 组件库:NaiveUI | |
| 流程编排组件:VueFlow | |
| 样式体系:Tailwind CSS 3.4+ | |
| 构建工具:Vite 5.0+ | |
| 工程模板:Vben5 | |
| 后端基础架构 | 核心框架:Spring Boot 3.x |
| 运行时:JDK 17+ LTS | |
| 关系型数据库:MySQL 8.0+ | |
| 缓存中间件:Redis(支持高可用) | |
| ORM:MyBatis-Plus 3.5+ | |
| 模型集成层:LangChain4j | |
| 权限框架:Sa-Token | |
| 工具库:Hutool | |
| 数据存储与检索 | 搜索引擎:Elasticsearch |
| 向量数据库:Milvus | |
| 轻量向量检索:Pgvector | |
| 大模型服务支持 | 国内平台:DeepSeek、阿里百炼、硅基流动等 |
| 扩展支持:百度千帆、智谱、豆包等 | |
| 国际平台:OpenAI / Azure OpenAI、Google Gemini | |
| 私有化部署:Ollama、Xinference、vLLM、GpuStack | |
| 部署硬件要求 | CPU:支持 Intel/AMD x86_64 及国产 CPU(建议 8 核起) |
| 内存:16GB 起,推荐 32GB+ | |
| 存储:NVMe SSD 50GB 起 | |
| 系统:CentOS 8+、Ubuntu 20+、RHEL 8+ | |
| GPU:常规场景非必需(私有模型训练/推理除外) |
功能清单
平台提供以 Agent 为核心的 AI 应用开发能力,集成 Workflows 可视化编排、RAG 知识检索、MCP/插件扩展、模型网关调度与权限安全治理,支持从构建、发布到审计运维的完整流程。
| 功能模块 | 功能清单 | ||
|---|---|---|---|
| 开源版 | 商业版 | ||
| 探索模块 | 应用体验(支持免登录访问) | ✅ | ✅ |
| Agent 智能体开发 | Agent 应用管理(基础对话/智能助手) | ✅ | ✅ |
| 配置中心(模型参数、系统提示词、温度等) | ✅ | ✅ | |
| 知识库检索(RAG 混合检索) | ✅ | ✅ | |
| 外部数据连接(数据库、MCP 服务、自定义插件) | ✅ | ✅ | |
| SearchTool 按需路由(tool_search_tool) | ❌ | ✅ | |
| 动态检索工具挂载(search_database / search_knowledge_base) | ❌ | ✅ | |
| 渠道接入、会话日志与统计看板 | ✅ | ✅ | |
| 多模态交互(OCR、语音合成、模型解析) | ❌ | ✅ | |
| 企业数据库直连(MySQL、PostgreSQL、Oracle 等) | ❌ | ✅ | |
| 意图识别与业务参数提取 | ❌ | ✅ | |
| Skills 能力中心 | Skills 模块管理与应用关联 | ❌ | ✅ |
| Skills + Sandbox 双链路接入(Agent / Workflow) | ❌ | ✅ | |
| 本地技能与沙箱技能协同调用 | ❌ | ✅ | |
| Skill / PluginSearchNode / McpSearchNode | ❌ | ✅ | |
| 知识应用与文档构建 | 知识库配置与管理 | ✅ | ✅ |
| 语义分段策略配置(正则、AST、滑窗等) | ✅ | ✅ | |
| 分段内容编辑与增量更新 | ✅ | ✅ | |
| RRF 融合与混合召回 | ✅ | ✅ | |
| Docling 文档解析引擎 | ❌ | ✅ | |
| PaddleOCR 文字识别集成 | ❌ | ✅ | |
| Workflows 工作流引擎 | 可视化流程编排 | ❌ | ✅ |
| 流程控制节点(Switch、Loop、批处理子图) | ❌ | ✅ | |
| IF / Loop / Intention 多条件组合(AND / OR) | ❌ | ✅ | |
| Loop 终止条件与复杂循环控制增强 | ❌ | ✅ | |
| AI 节点能力(LLM 路由、知识检索、意图分类) | ❌ | ✅ | |
| 企业服务节点(爬虫、报表、第三方 API) | ❌ | ✅ | |
| 代码执行节点(OpenSandbox 隔离运行) | ❌ | ✅ | |
| 画布指针模式与多节点框选批量移动 | ❌ | ✅ | |
| 节点展开/缩放体验优化与状态持久化恢复 | ❌ | ✅ | |
| 工作流历史操作面板(上一步/下一步) | ❌ | ✅ | |
| 变量追踪与任务调度(Tracing、XXL-JOB) | ❌ | ✅ | |
| 企业辅助能力 | 素材库与 OSS 资源管理 | ❌ | ✅ |
| 低代码脚手架平台 | 表单搭建与 CRUD 代码/SQL 生成 | ❌ | ✅ |
| Text2SQL 数据能力 | JDBC 数据源接入与管理 | ❌ | ✅ |
| DDL 释义与业务语义标注 | ❌ | ✅ | |
| 统计分析结果可视化展示 | ❌ | ✅ | |
| 第三方平台集成 | Dify、Coze ChatBot应用对接与迁移 | ✅ | ✅ |
| Docker Compose 一键接入 SearXNG、Xinference 等服务 | ✅ | ✅ | |
| MCP 服务与插件扩展 | MCP Server 对接(支持 HTTP、Stdio) | ✅ | ✅ |
| JSON Schema 参数化配置面板 | ✅ | ✅ | |
| Java SDK 与 @McpServer 注解开发支持 | ✅ | ✅ | |
| Function Call 自定义 HTTP 插件(@Tool) | ✅ | ✅ | |
| 多模态模型能力 | 多模型统一接入与编排 | ❌ | ✅ |
| 图像生成模型接入(如 Qwen-Image、豆包) | ❌ | ✅ | |
| 音频能力(TTS、ASR) | ❌ | ✅ | |
| 视频生成 | ❌ | ✅ | |
| AI 文档排版与编辑 | ❌ | ✅ | |
| 合规与安全 | 敏感词策略管理与拦截 | ❌ | ✅ |
| 文档审查与清洗(Apache Tika) | ❌ | ✅ | |
| 统一身份认证(SSO、OAuth) | ❌ | ✅ | |
| 终端与渠道接入 | 企业 IM 接入(微信、飞书、企业微信、钉钉) | ❌ | ✅ |
| Iframe 嵌入与标准 Web 接口接入 | ❌ | ✅ | |
| 富文本卡片消息渲染 | ❌ | ✅ | |
| Web SDK 悬浮助手组件 | ❌ | ✅ | |
| 模型动态接入 | 多模型统一动态接入能力 | ✅ | ✅ |
| 本地推理端点接入(Xinference、Ollama、vLLM) | ❌ | ✅ | |
| 向量数据库统一接入(Milvus、Elasticsearch 等) | ✅ | ✅ | |
| 审计与成本监控 | 会话链路审计(ChatListener) | ❌ | ✅ |
| 按 Token 与调用量成本统计 | ❌ | ✅ | |
| 多维成本报表与图表分析 | ❌ | ✅ | |
| RBAC 权限管理 | 用户、角色与权限配置 | ✅ | ✅ |
| 细粒度权限控制(前端路由与 API 权限) | ✅ | ✅ | |
| 后台操作日志 | ✅ | ✅ | |
| 用户数据隔离 | ❌ | ✅ | |
| 商务合作与维保 | 基础使用与部署文档 | ✅ | ✅ |
| 企业版开发手册与二次开发指引 | ❌ | ✅ | |
| 版本升级与功能更新支持 | ❌ | ✅ | |
| 技术支持与故障响应服务 | ❌ | ✅ |