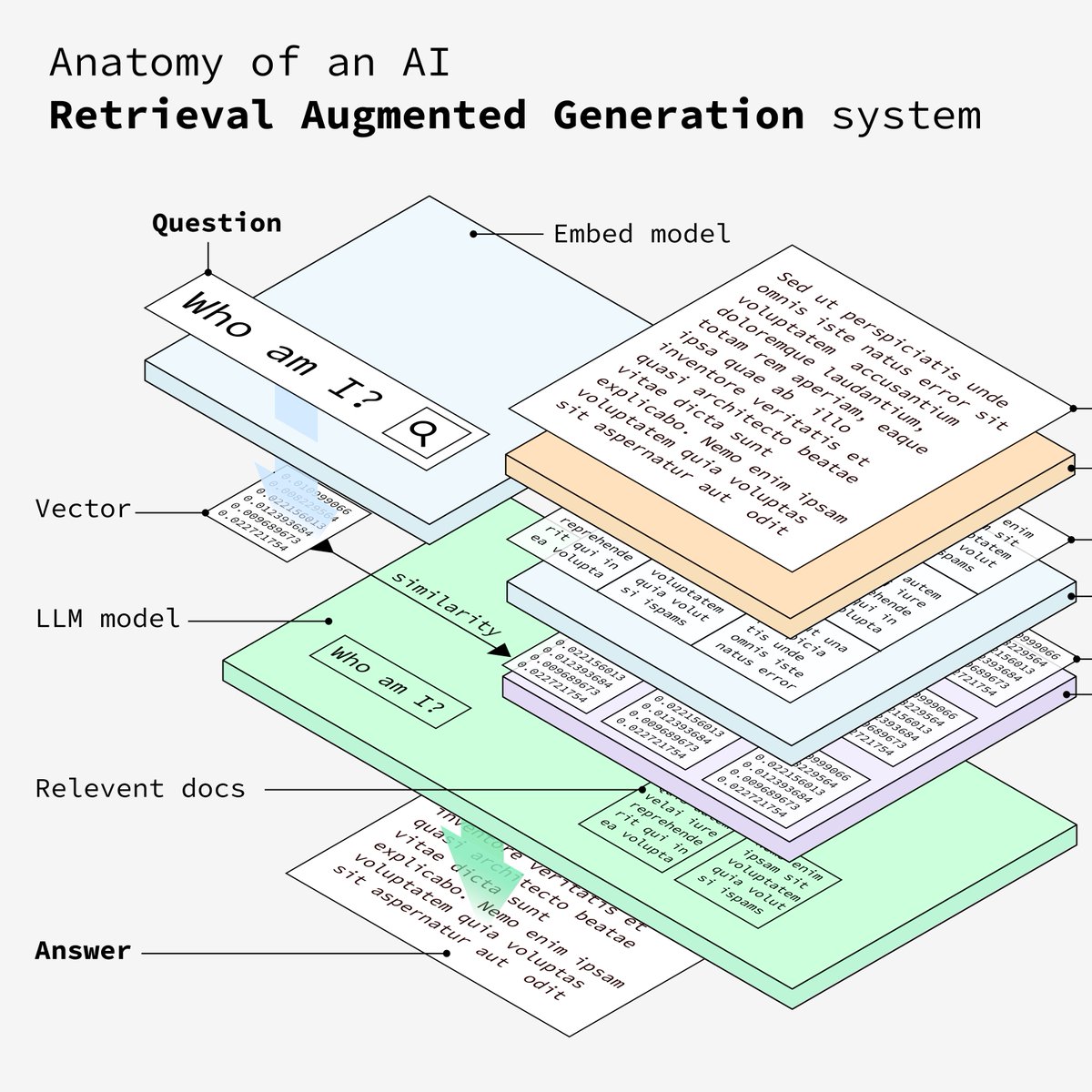
LangChain如何实现RAG?
Baptiste Adrien分享了使用 Vercel和NextJS 开发 RAG(检索增强生成)系统,使用图例详细介绍RAG系统的设计流程,非常直观详细,对于学习大模型AIGC产品设计流程非常有帮助。
1. 文档处理
开发RAG系统的第一步是准备文档,这些文档将作为RAG系统的基础输入数据。

2. OCR文本提取
接下来,文档由 OCR(图片转文本)模型进行处理。如果需要,该模型会提取文本。

3. 文本拆分
文本被分成更小的、易于管理的部分。这种分块可以在后期进行更有效的处理和分析。

4. 文本嵌入
然后每个文本块都会通过嵌入模型。该模型将块转换为向量,即捕获文本语义的数字表示。
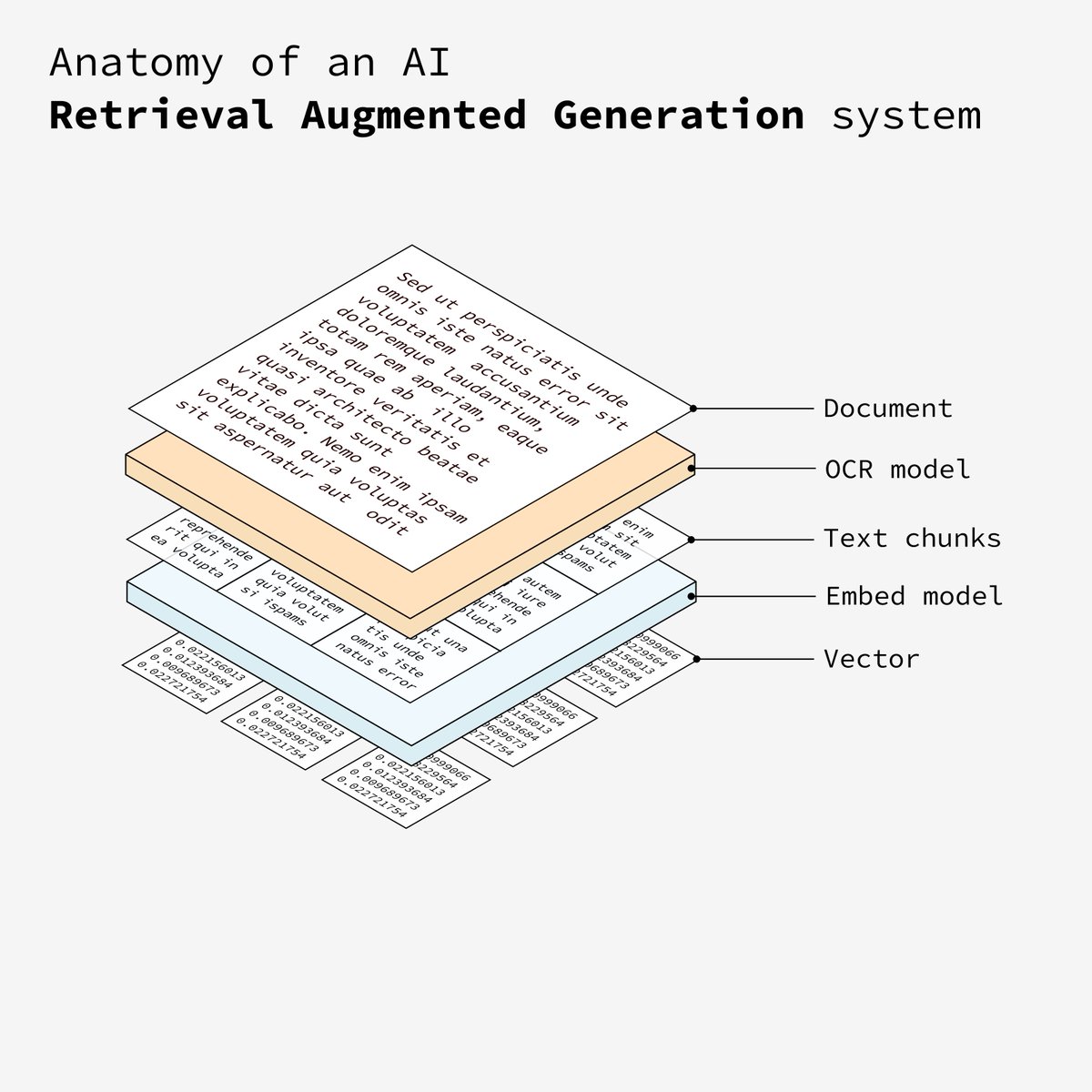
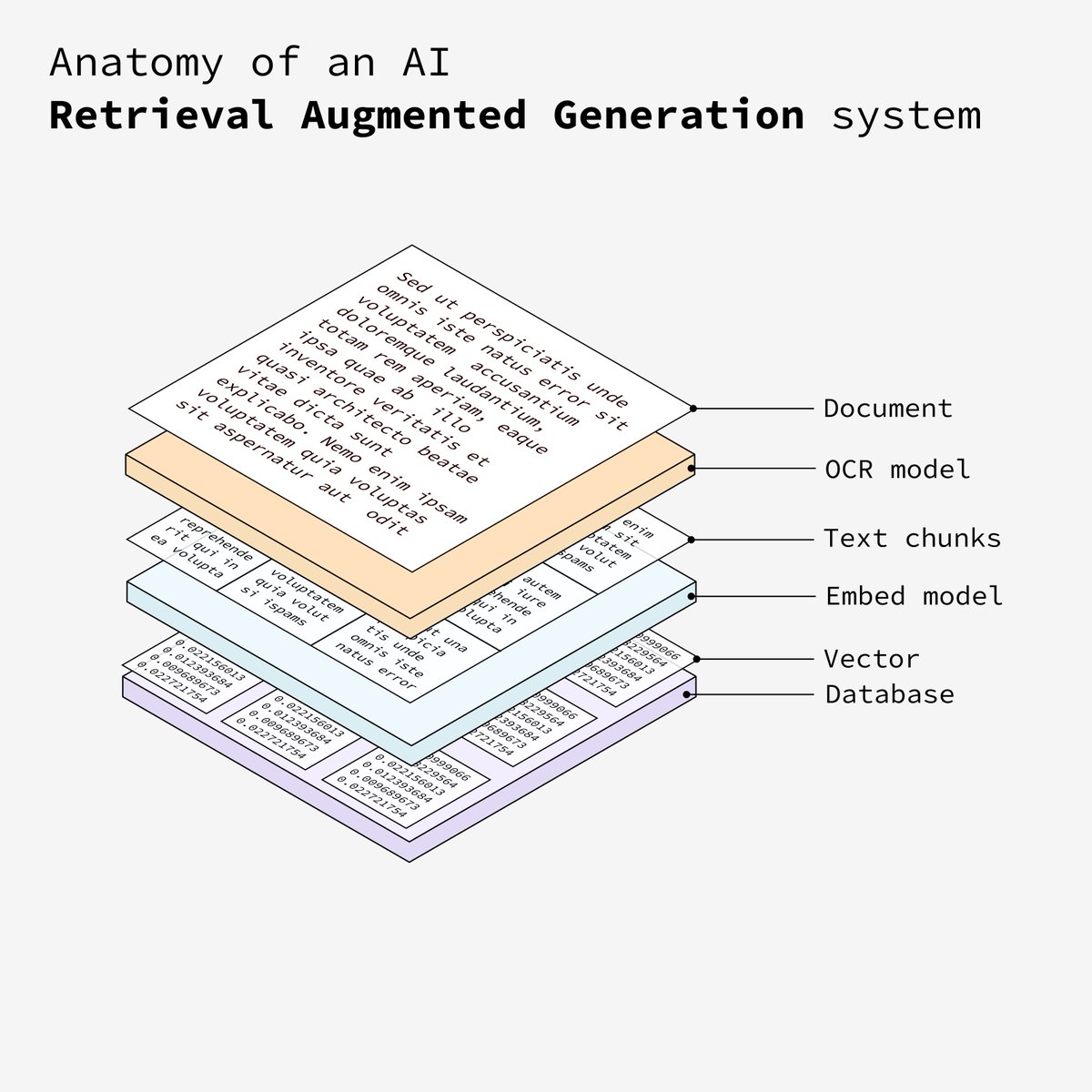
5. 向量存储
上一步将文本转换为向量数据库需要存储到向量数据库中(例如PgVector),该数据库允许系统根据语义相似性有效地检索相关信息。
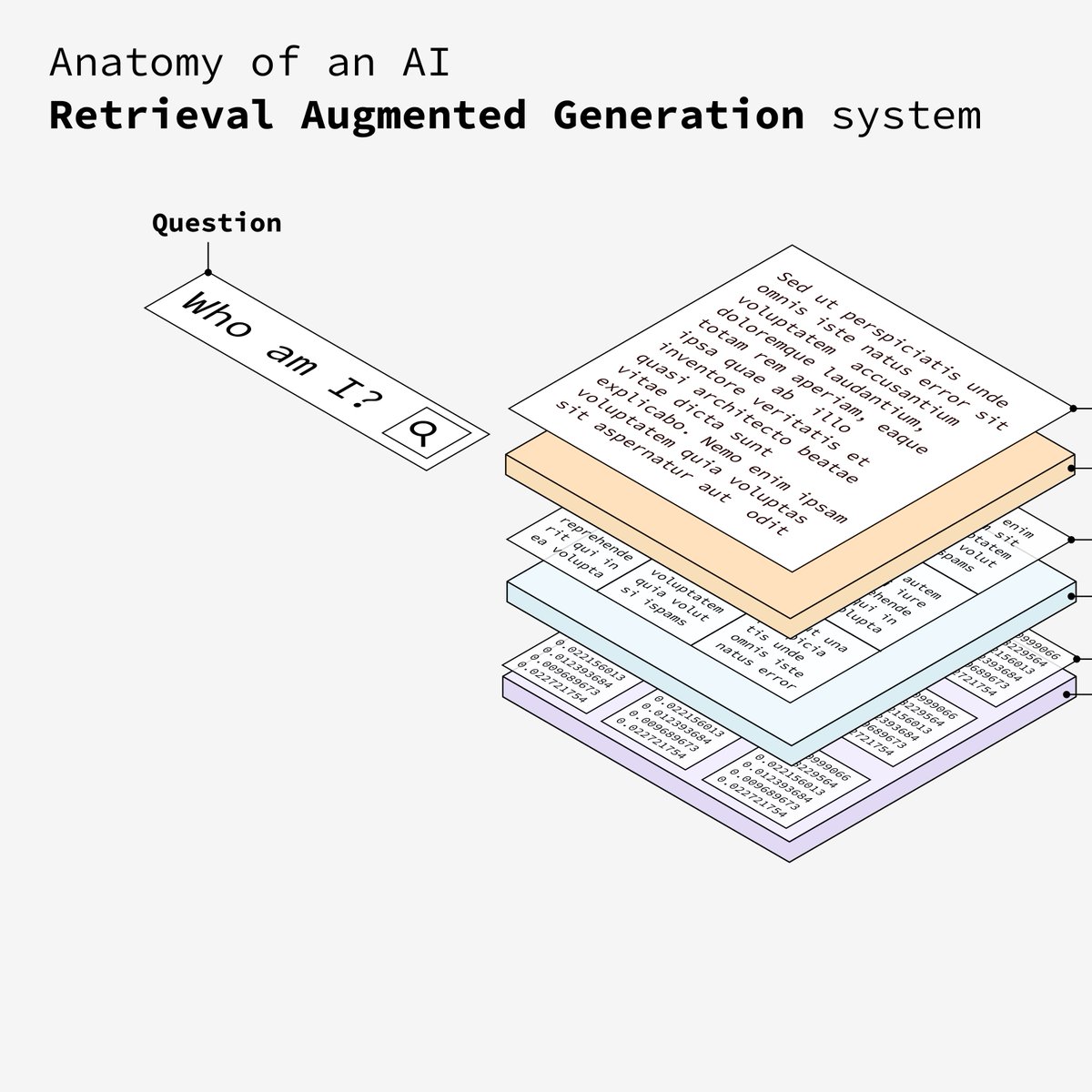
6. 输入问题并检索
用户向系统输入问题,该问题将用于从矢量数据库中检索最相关的信息(其实就是从向量库中匹配相似的数据)。
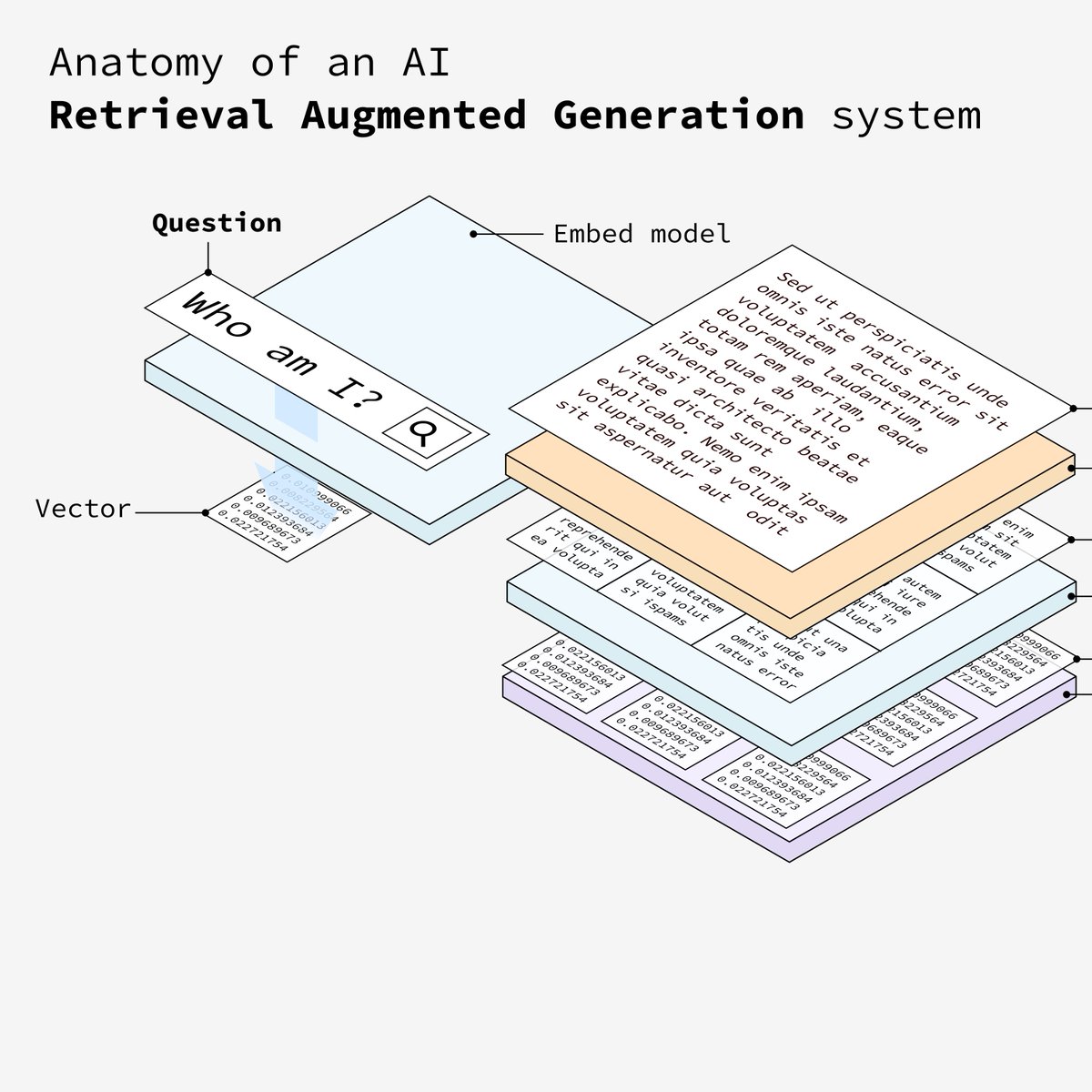
7. 输入嵌入
接下来需要将用户输入的问题转换成相同的向量纬度,只有转换成和文档相同的向量纬度,确保了问题和文本块都位于同一向量空间中,才能从向量数据库中匹配到相似的数据
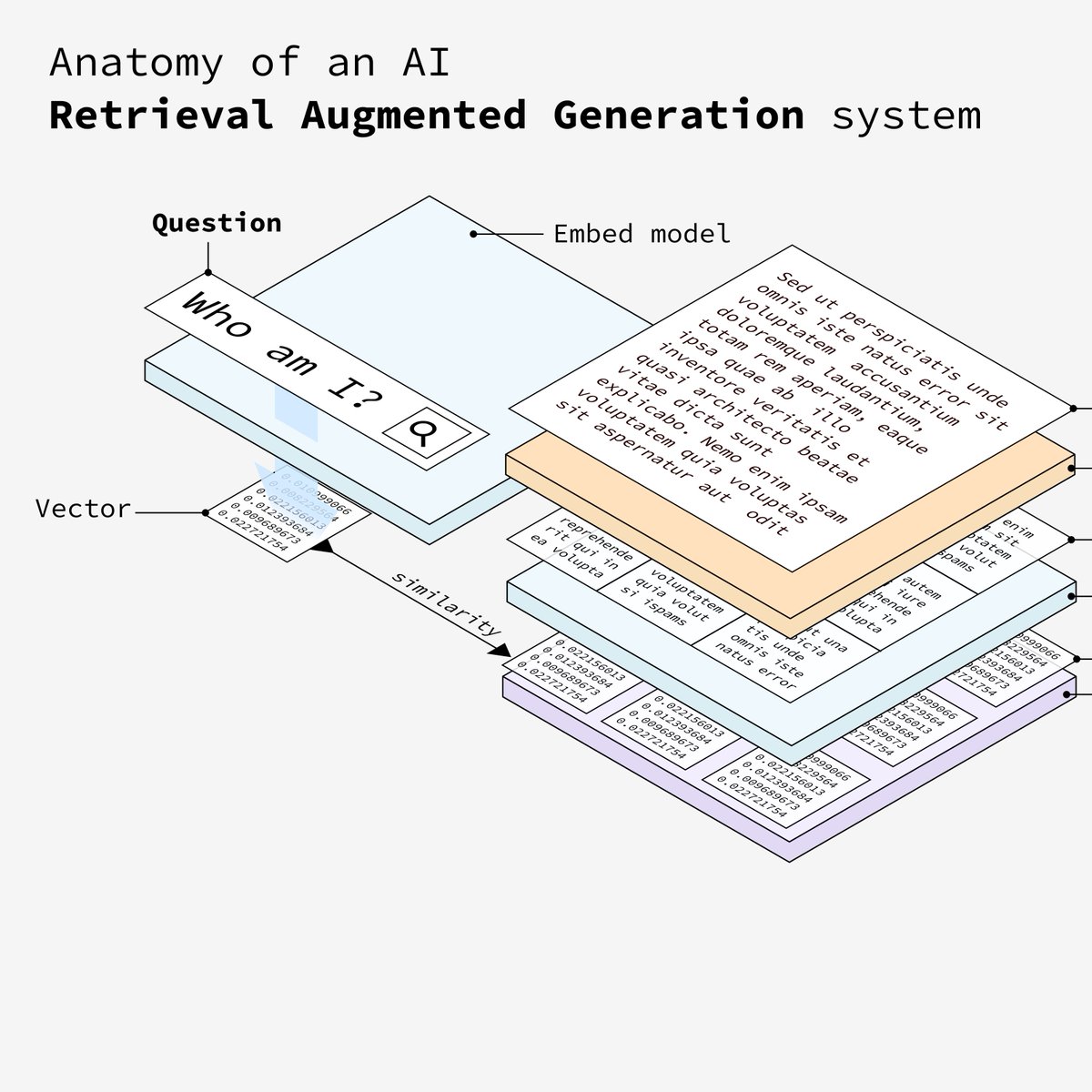
8. 向量匹配
同上,将嵌入后的问题在向量存储库中检索匹配相似的数据
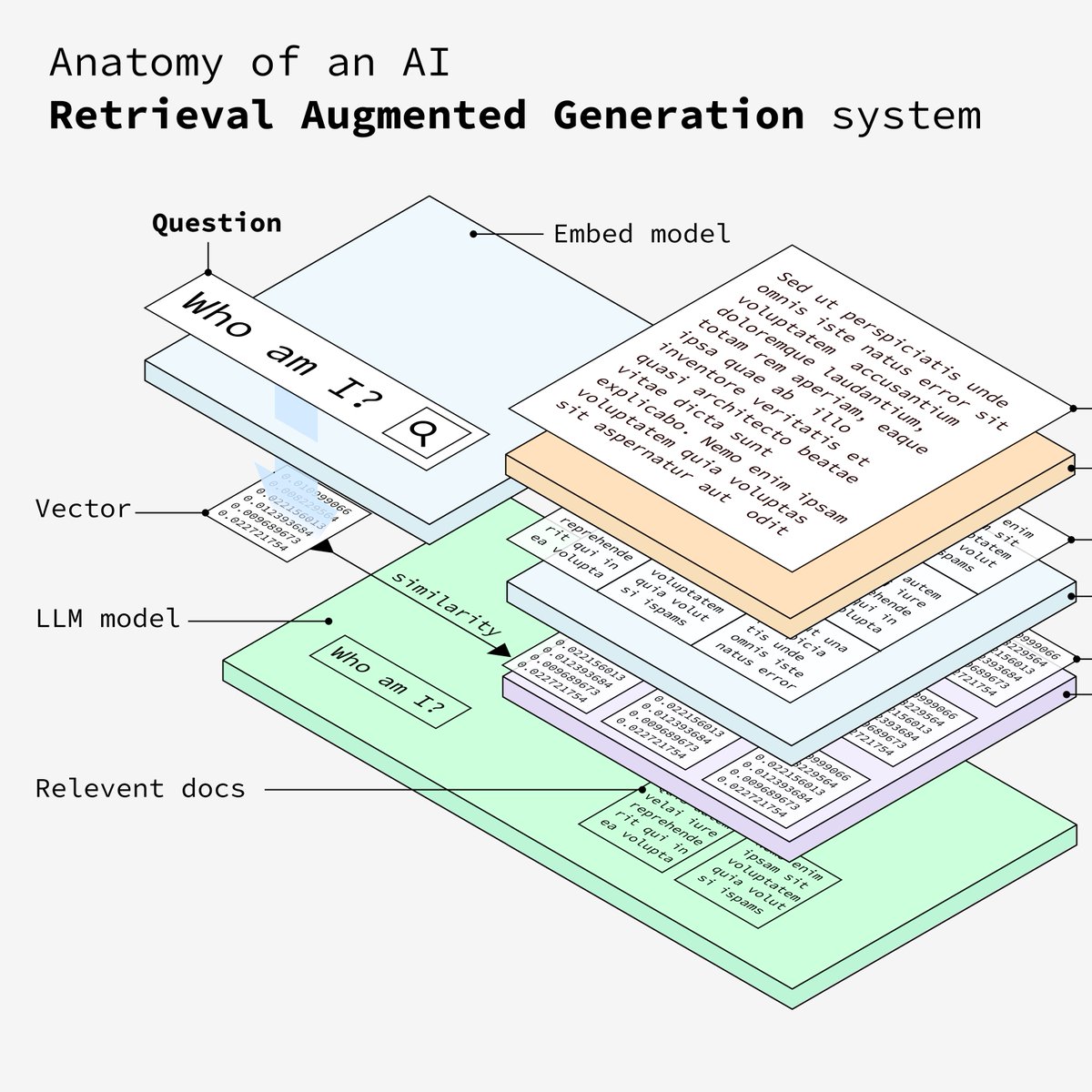
9. 数据处理
从向量库中匹配到相似的数据后,系统将交由LLM 处理相关信息以对用户的问题制定详细的答案。
10. 数据呈现
最终,LLM将针对用户的问题,并结合向量库中匹配到的相似的数据分析,输出最终的语义化文本内容给用户