在LangChat中配置模型
LangChat支持动态配置国内外数十家AI大模型,只需要在AIGC平台 -> 模型管理页面 配置中配置大模型即可,配置后系统会动态刷新配置,及时应用。
配置官方模型
官方模型指的是使用官方渠道购买的模型Key,例如openai官方key就是在https://openai.com/官网购买的。
对于这种方式,只需要按照LangChat模型配置页面,在左侧点击不同的模型供应商配置即可。
注意:
- 除了Ollama这种本地模型必须配置BaseUrl之外,其他的官方模型其实都不需要配置BaseUrl
- 只需要按照模型供应商官方文档配置apiKey即可
- 对于使用第三方代理的情况,后面将详细说明
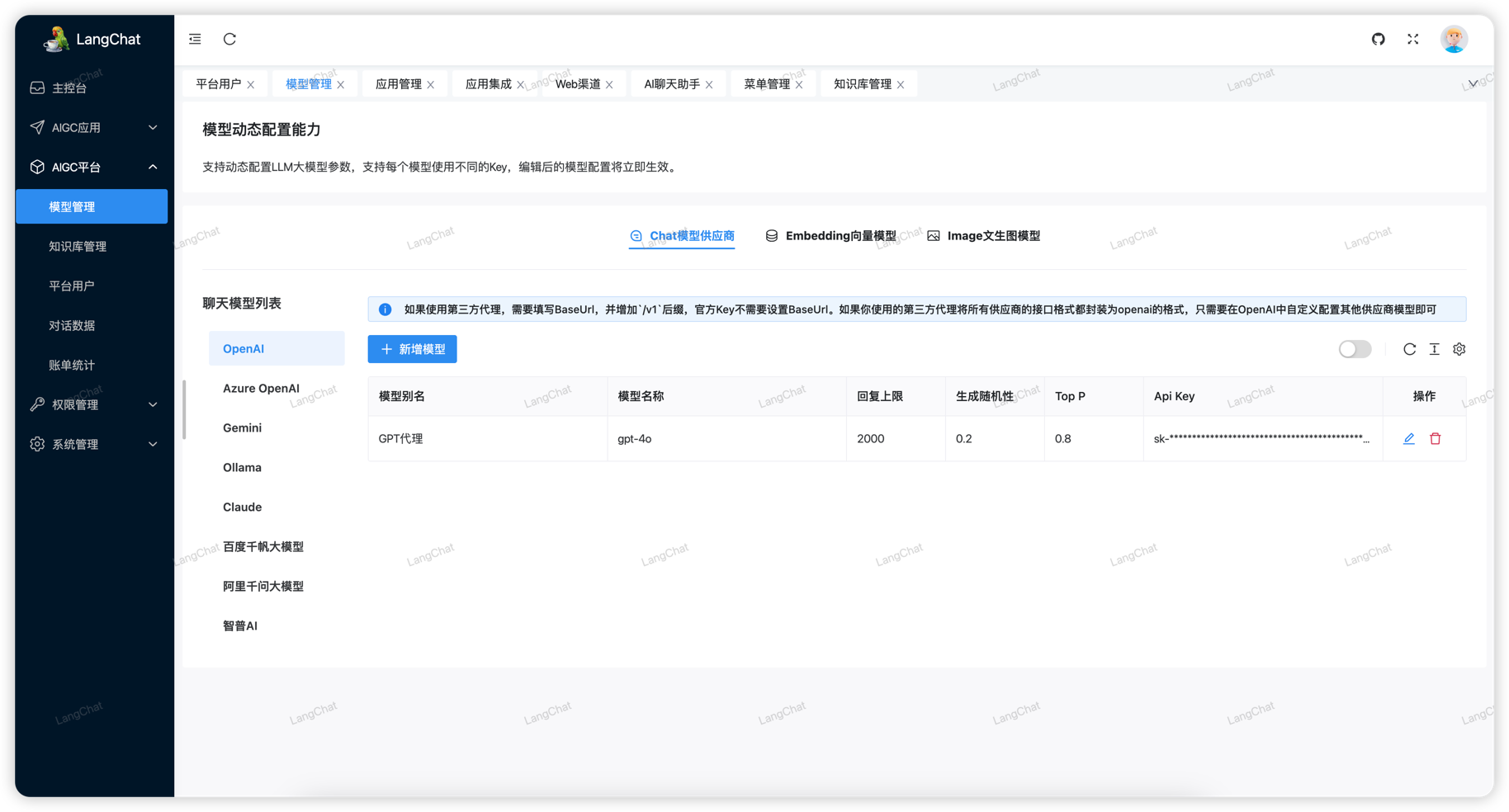
配置OpenAI
OpenAI官方只需要填写Api Key,然后选择一个模型即可。
注意:OpenAI接口默认是不可访问的,在本地一般我们会用科学上网实现,但是在服务器上一般必须通过代理实现
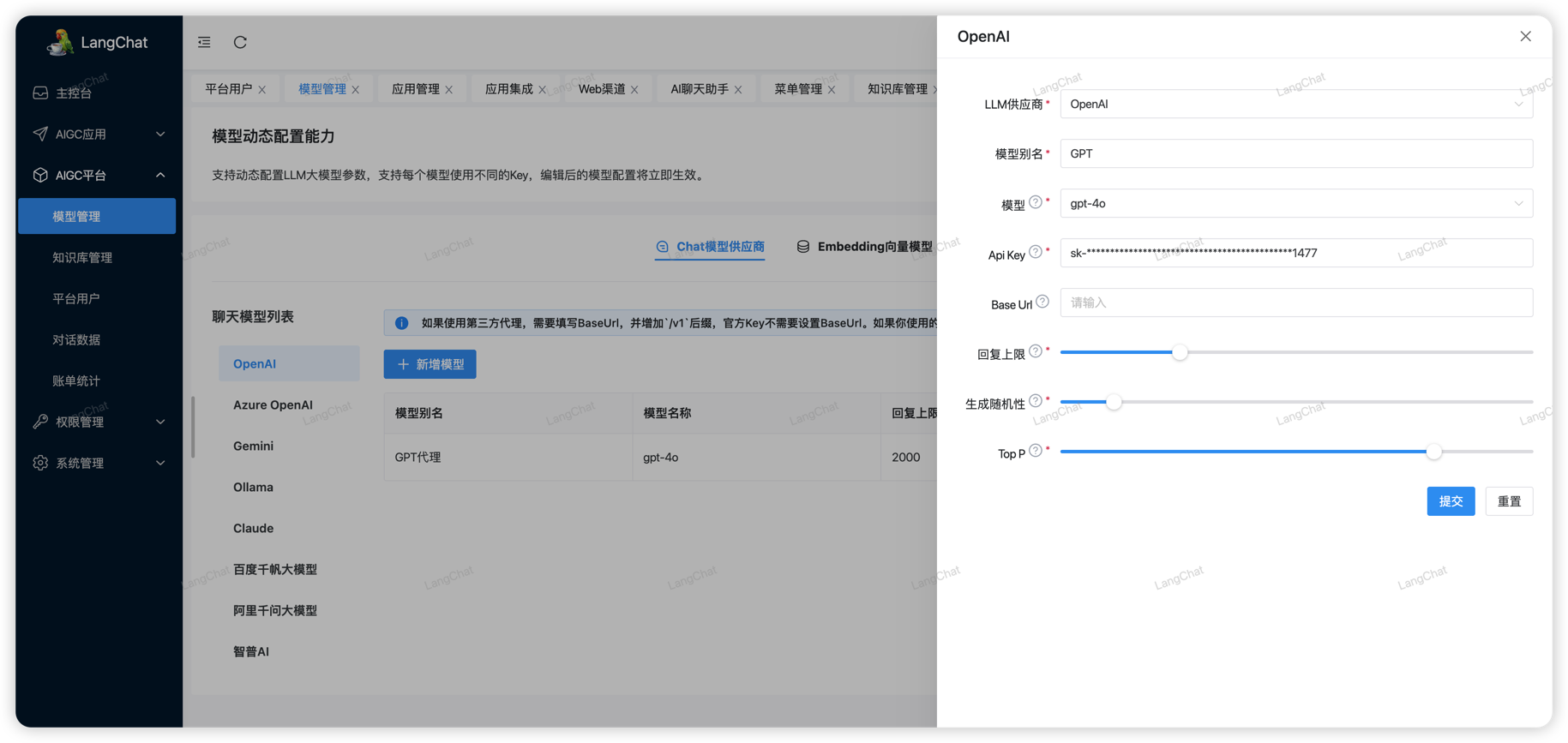
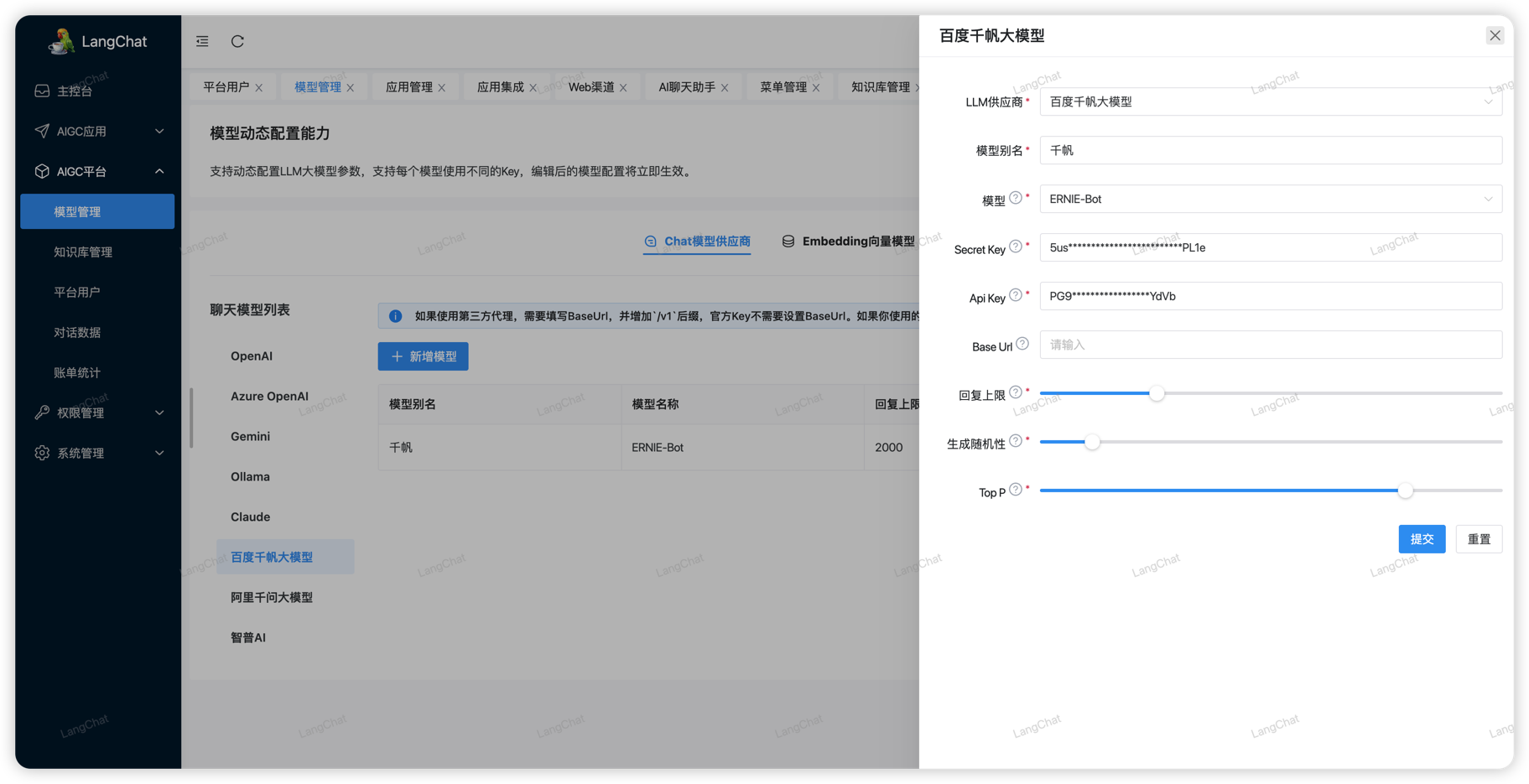
配置千帆大模型
百度千帆大模型对于新用户注册,可以免费使用限额限速的模型:ERNIE-Speed-8K,其他模型按量收费,需要自行开通
首先你需要注册百度智能云账号:https://console.bce.baidu.com/。注册成功后转到控制台页面,在如下页面配置你的应用:
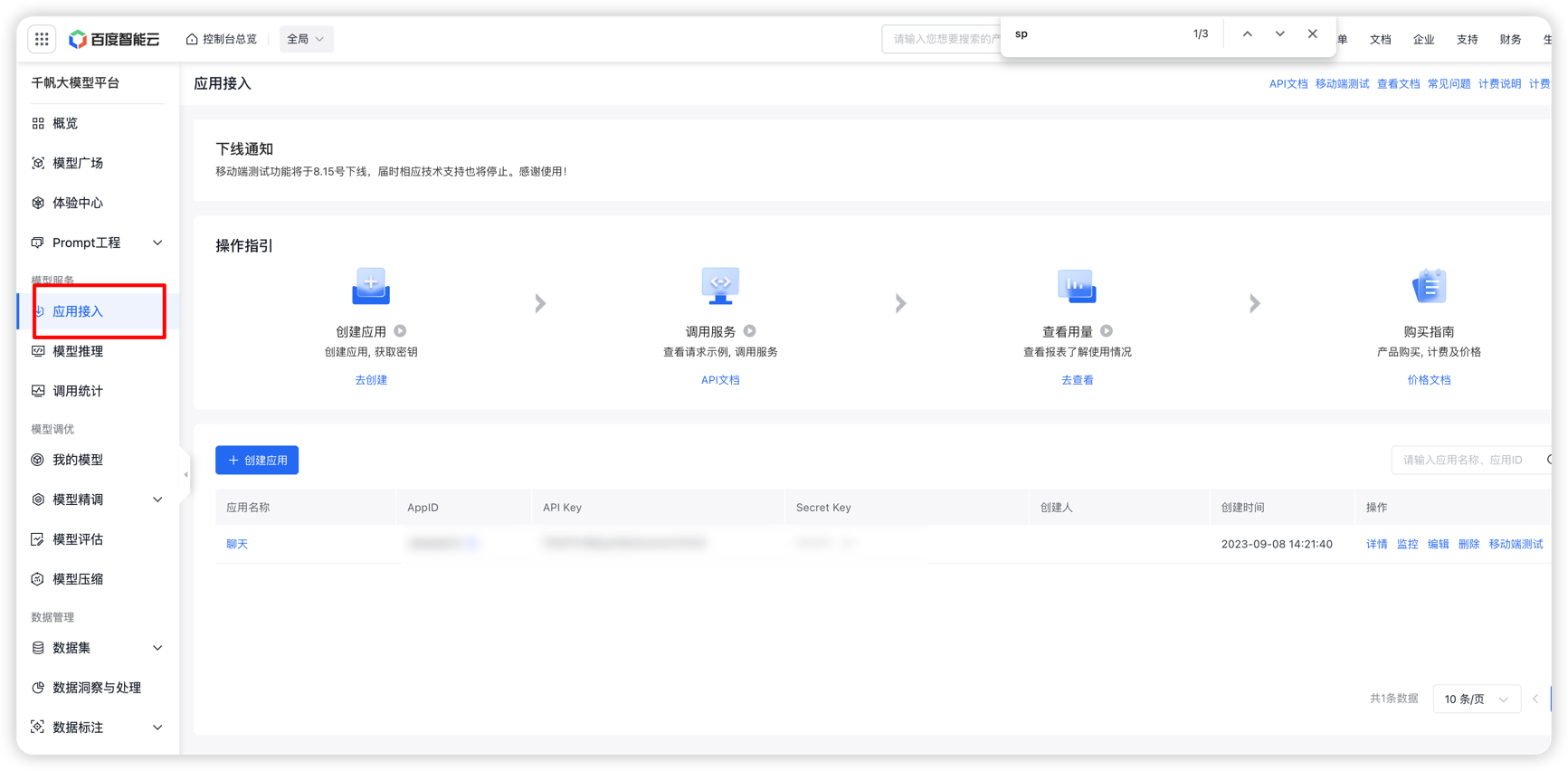
创建应用的时候会提醒你开通哪些模型,也可以在这里编辑需要开通的模型:(如果未开通直接调用api会提醒需要开通服务)
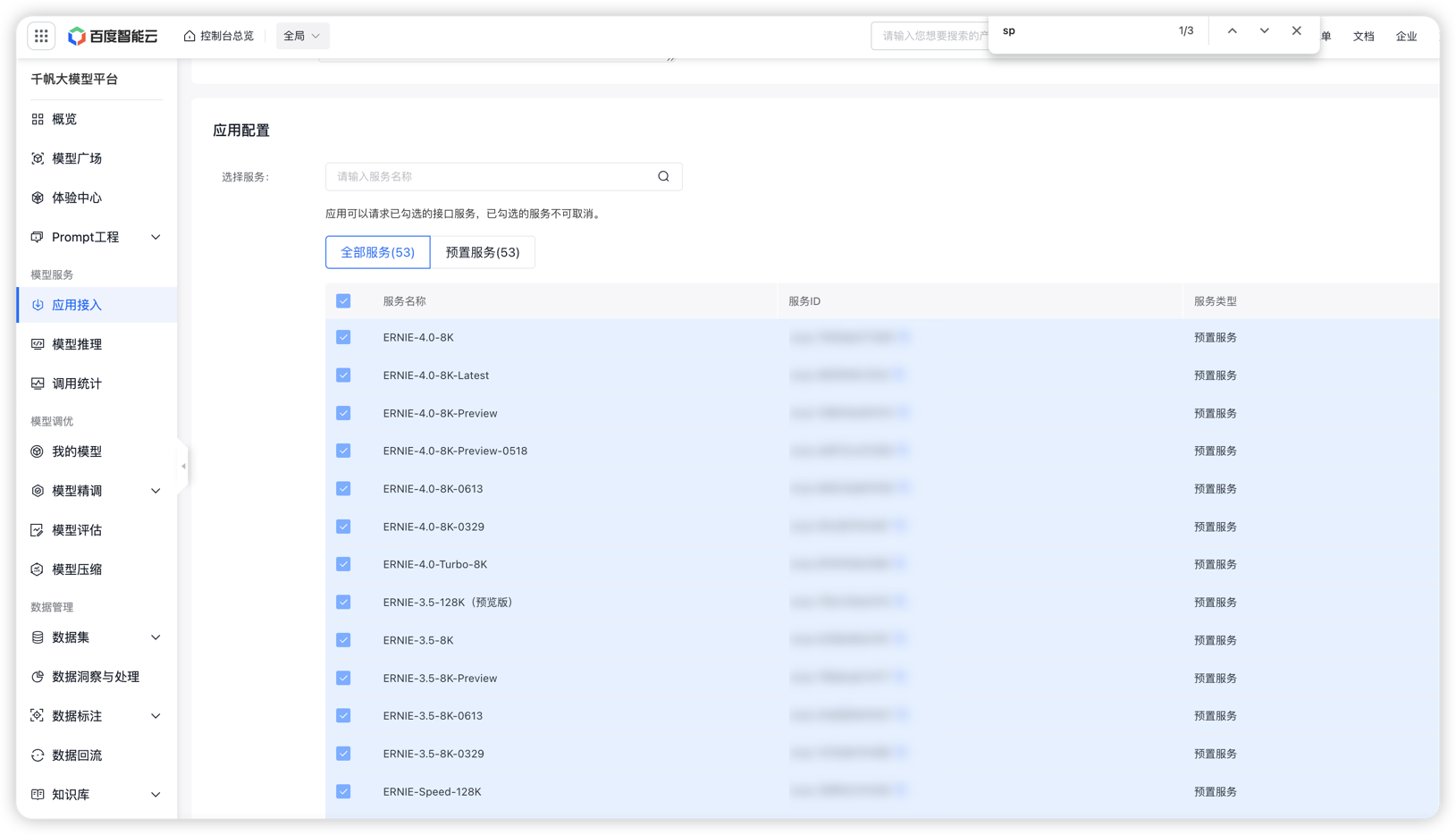
最终我们需要拿到上面创建应用的 Api Key Secret Key信息配置LangChat:
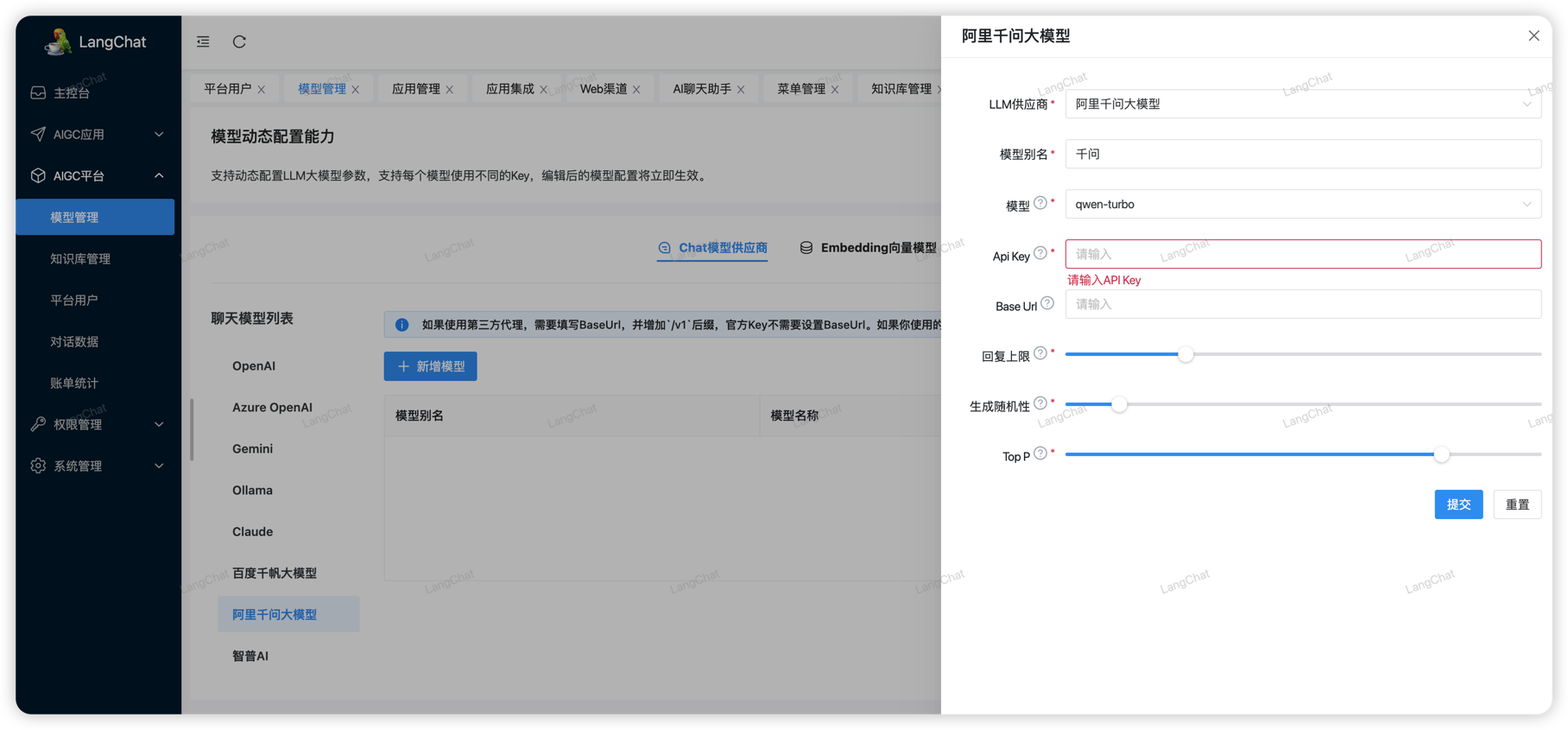
配置千问大模型
阿里千问模型服务,统一使用阿里的灵积服务平台:https://dashscope.aliyun.com/
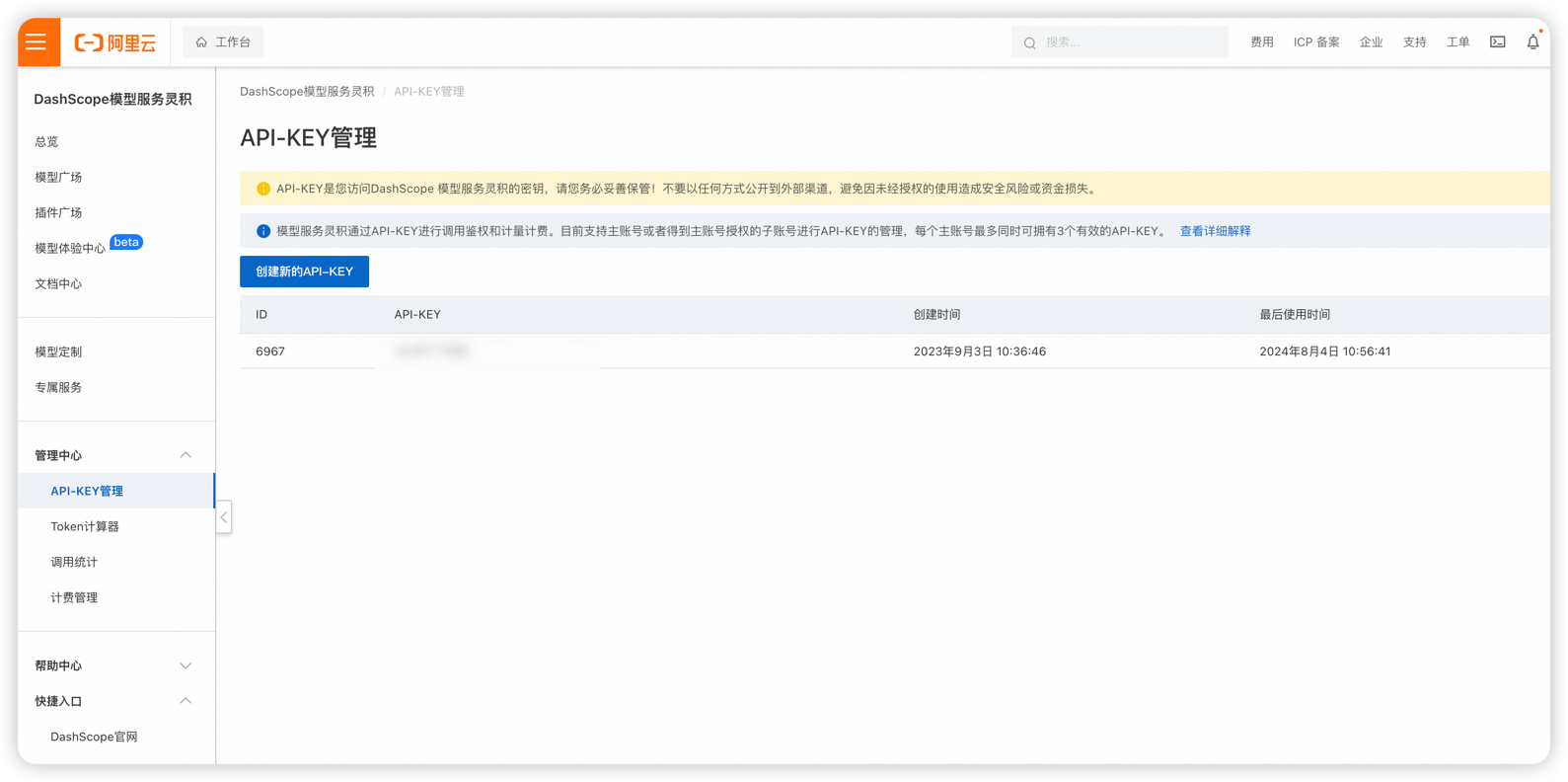
生成Api key后在LangChat模型管理页面配置模型信息即可,千问的模型也是按量计费。
配置智谱AI
官方文档看这里:
配置Ollama
Ollama是一种本地模型部署方案,Ollama简化了模型的部署方式,通过官方一行命令即可在本地下载并启动一个模型。重点:有很多不需要GPU的模型
Ollama的官网:https://ollama.com/library
例如我们想要在本地部署最新的Llama3.1模型:
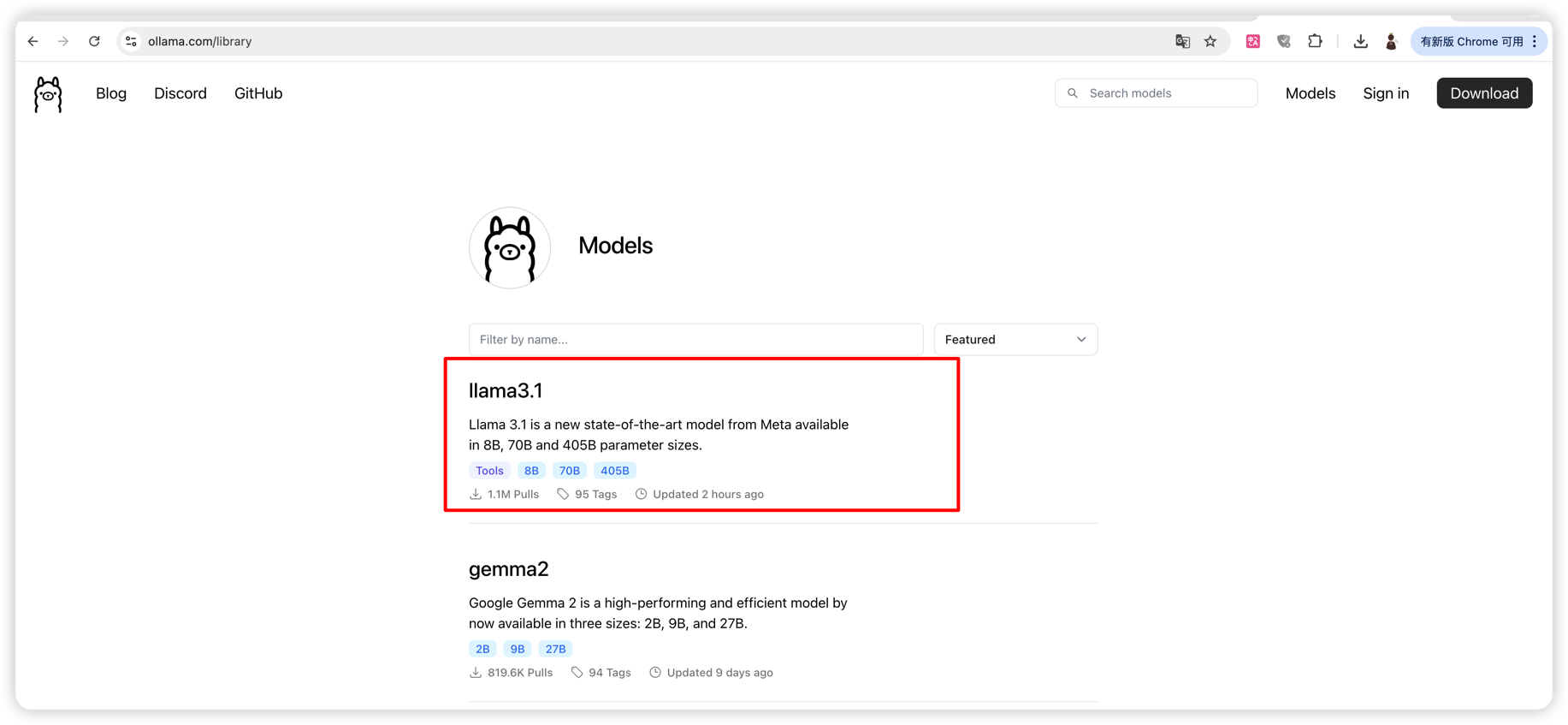
首先需要安装Ollama官方客户端,然后直接执行命令:
ollama run llama3.1默认会下载最小的模型,越大的模型对电脑配置要求越高,最小的模型一般不需要GPU也可运行(我使用的16/512 Mac book pro测试)。
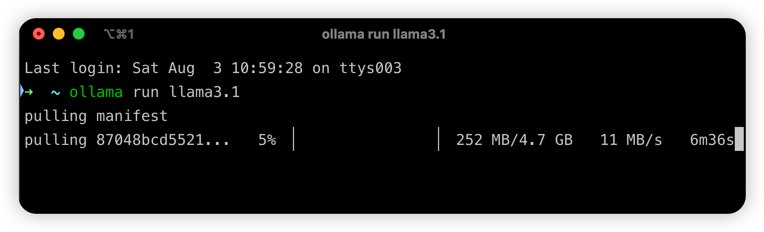
下载完成后会直接运行模型,如下,非常简单,我们可以直接通过命令行对话模型:
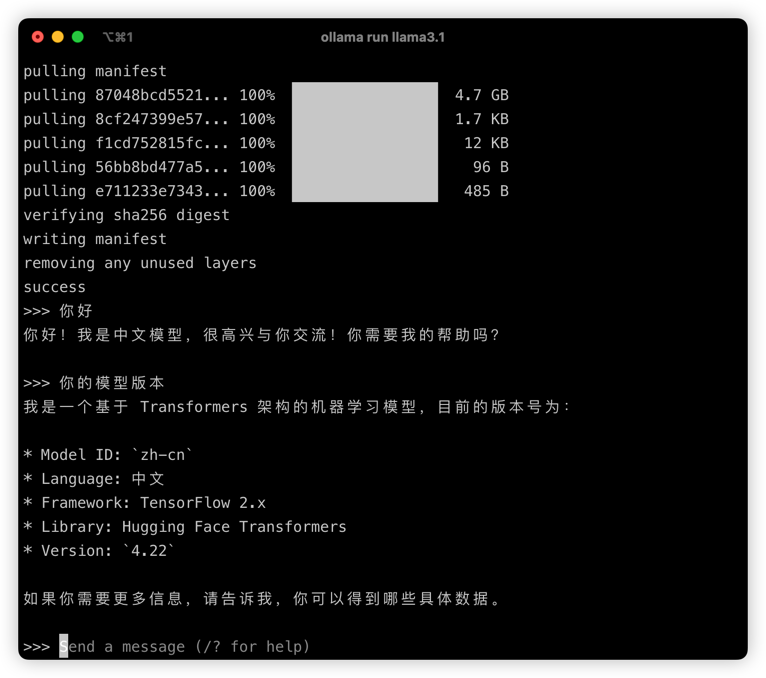
配置Ollama
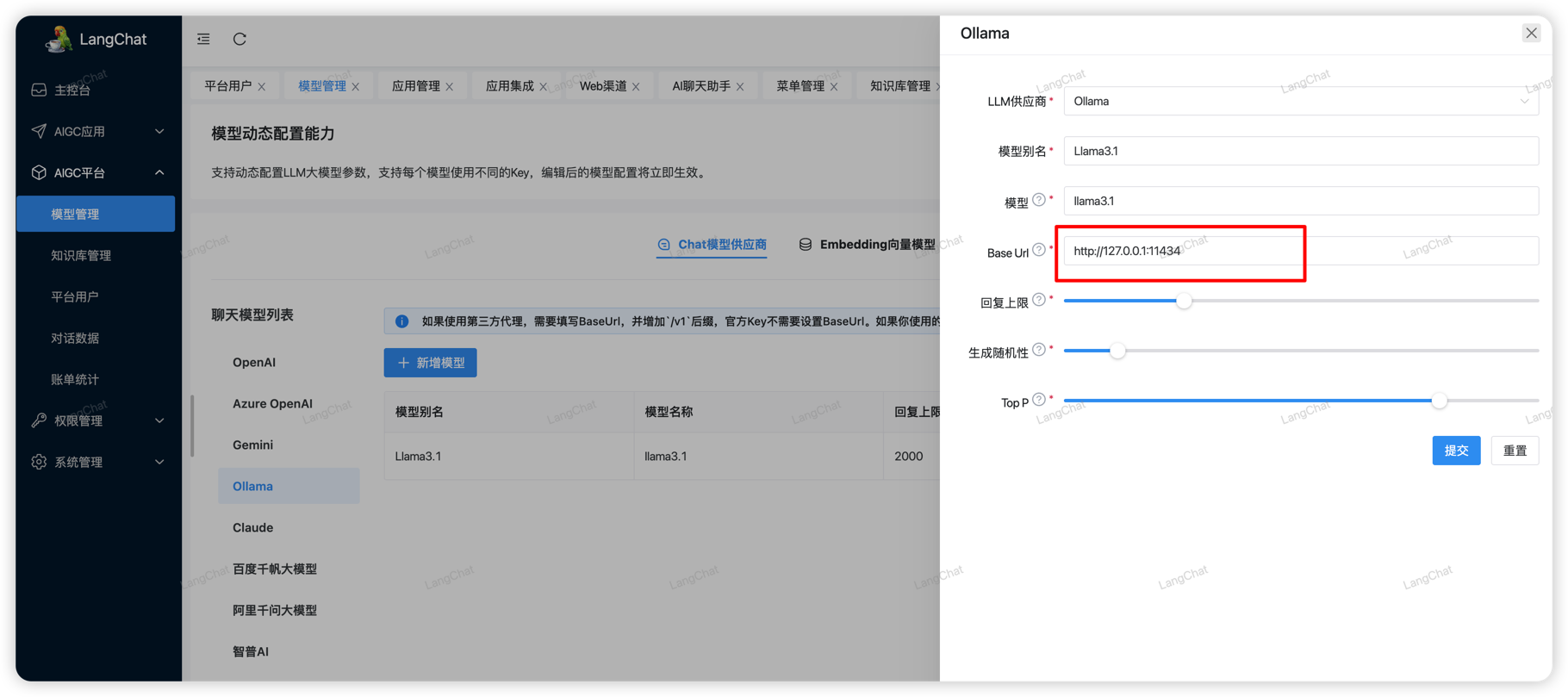
启动完成后,Ollama默认会暴露一个http端口:http://127.0.0.1:11434 。也就是我们最终会使用http://127.0.0.1:11434/api/chat 接口和Ollama模型聊天。
首先我们需要在LangChat模型管理页面配置Ollama模型信息,这里的BaseUrl必须填写上述地址,然后【模型】填写你运行的模型名称即可:
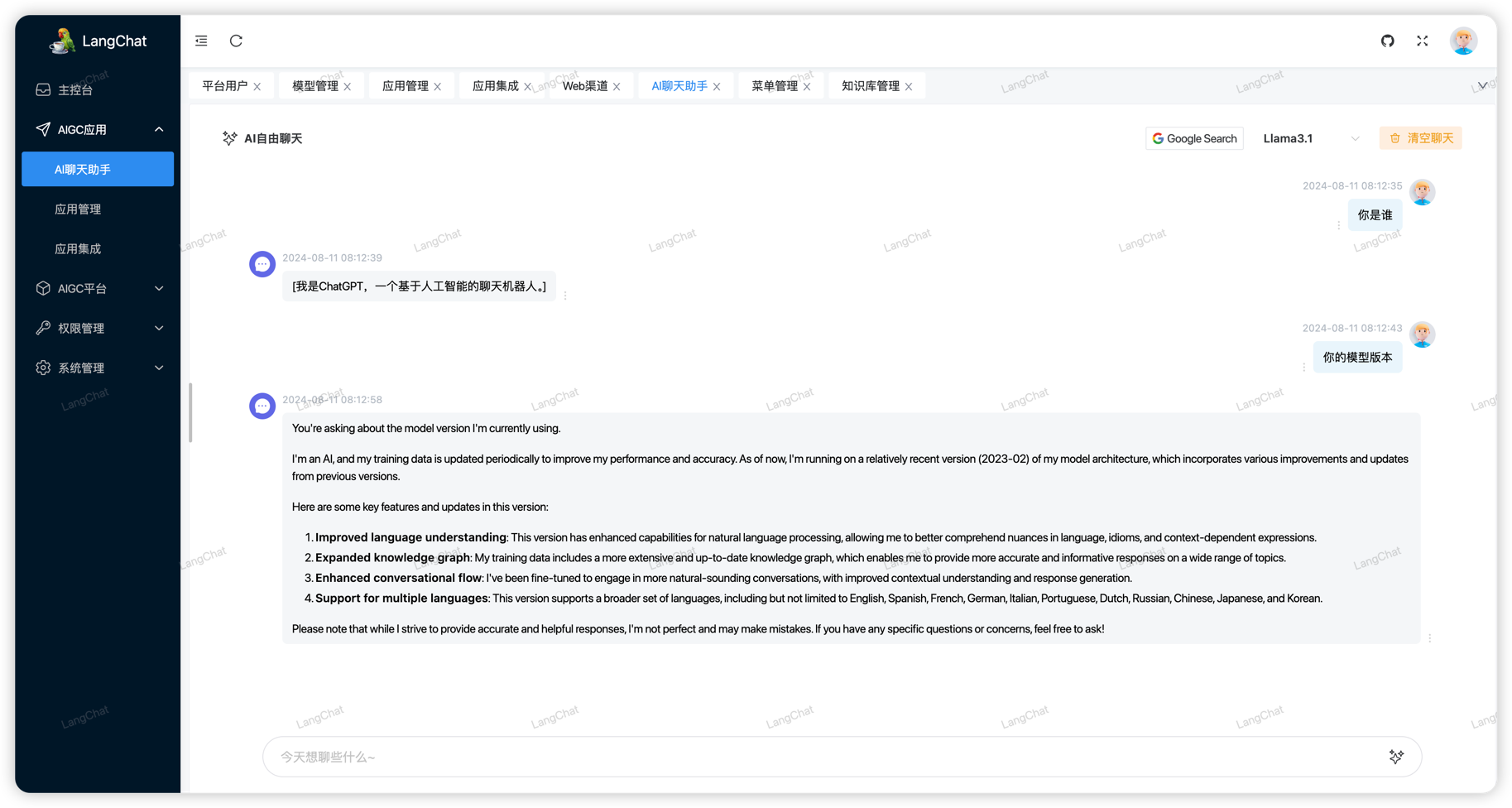
测试效果如下,在LangChat的聊天助手页面的右上角选择刚刚配置的Ollama模型即可快速使用。 (注意:最终的效果完全取决于模型的能力,和模型的参数大小有关,想要更好的效果、更快的响应速度就必须配置更高参数的列表,也就必须使用显存更高的机器)
配置Azure OpenAI
由于作者没有Azure OpenAI账号,所以这里不再演示,按照表单配置参数即可
官方文档看这里:
https://learn.microsoft.com/en-us/azure/ai-services/openai/
配置Gemini
注意:Google Gemini使用Google Vertex的认证方式,并不是直接填写api key就可以了,需要本地电脑安装一些google身份认证工具CLI
官方文档看这里:
配置Claude
官方文档看这里: