在LangChat中配置知识库
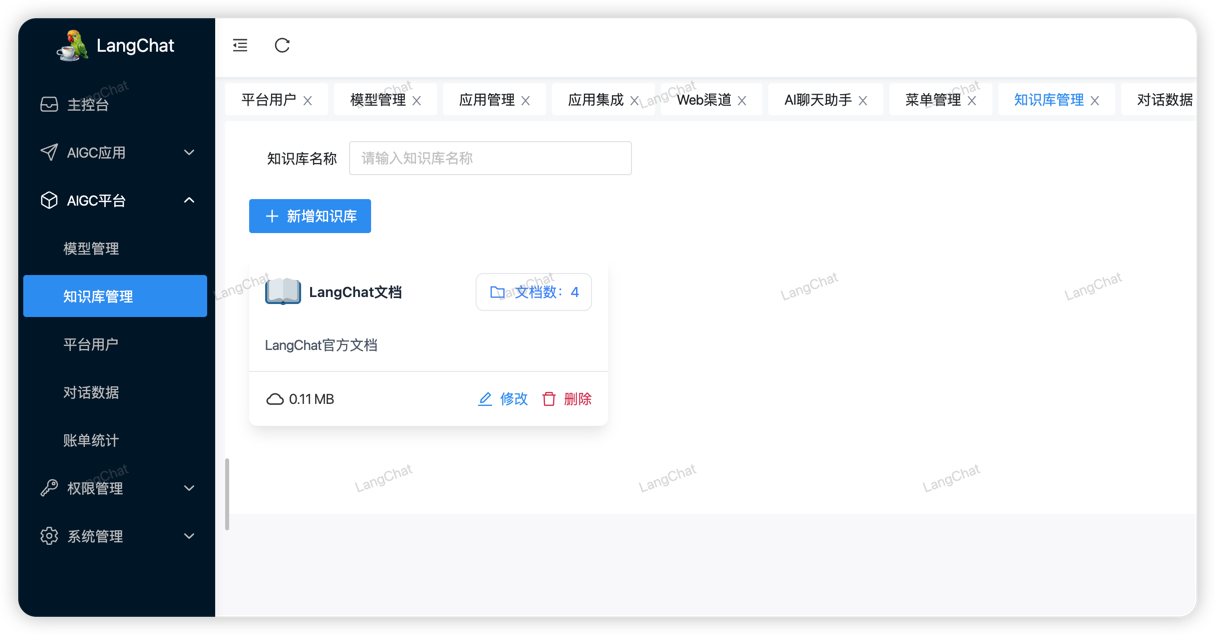
首先进入到LangChat的知识库管理页面:
导入知识库
可以自由创建知识库,创建完成后,即可进入配置页面,可以通过两种方式:导入文档、或者录入文本数据进行向量化解析。
为什么要向量化?简单理解就是:将文本内容转换成不同维度的有上下文关系的二进制数组数据,也就是将文本细化,可以更精确的匹配到相关联的文本关键词。
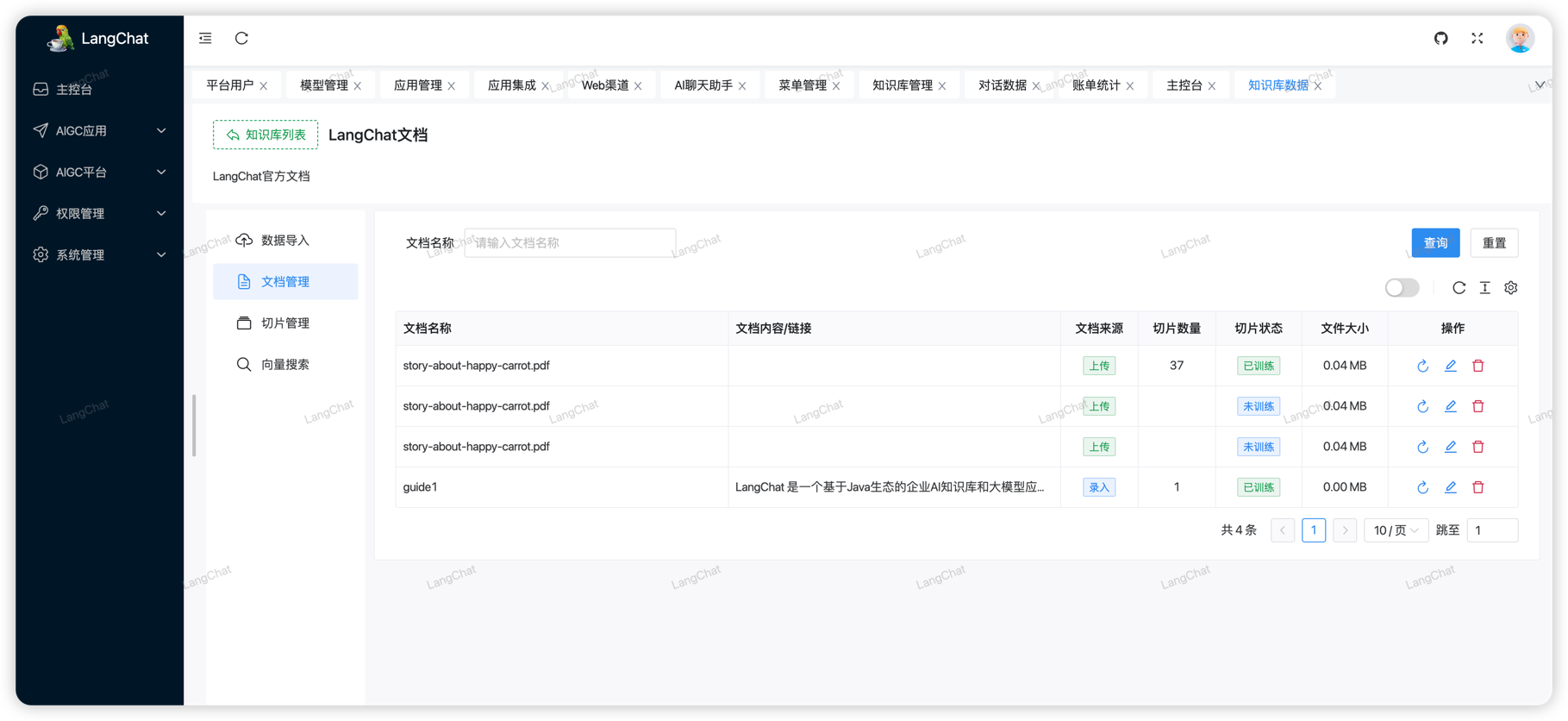
文档管理
上面导入的知识库文档,可以在这里搜索到,并且可以查看文档是否已经被训练(向量化),用户可以选择重新训练(将会删除向量数据库中原始数据并重新做Embedding)
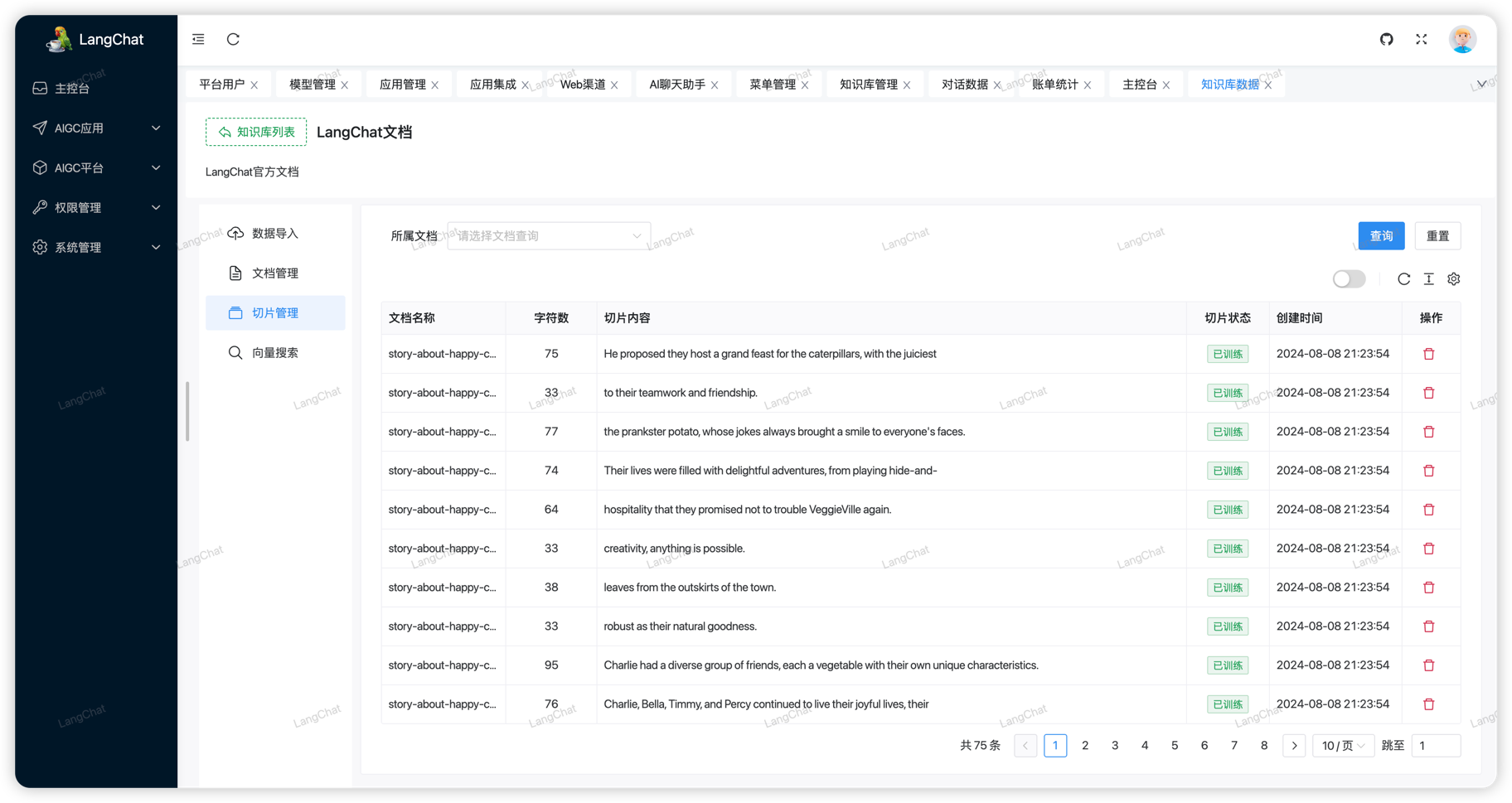
切片管理
同样的,上面导入了知识库文档后,系统将通过Embedding模型向量化文档数据。
为什么是切片? Embedding模型要将文档解析为向量数据,这些数据最终会存储到VectorStore向量数据库中, 而对于文档内容过多的时候会将一个文档拆分为多个部分进行向量化存储。(也有可能例如分段、分页等分割方式)。
在LangChat的切片管理页面可以轻松的查看到不同文档最终分割的切片数据集。
切片检索
如果熟悉RAG系统流程的朋友应该知道,RAG实际是通过将用户问题返回到向量数据库中匹配相似的文档,并将匹配结果吐给LLM,因此LLM能够在最小的样本数据中分析出来上下文的含义并做解答。
LangChat同样提供了可视化的检索页面,通过查询某个关键词,从向量数据库中检索相似的文本,这和SQL的 select * from db where keywork like 'xxx' 是类似的。
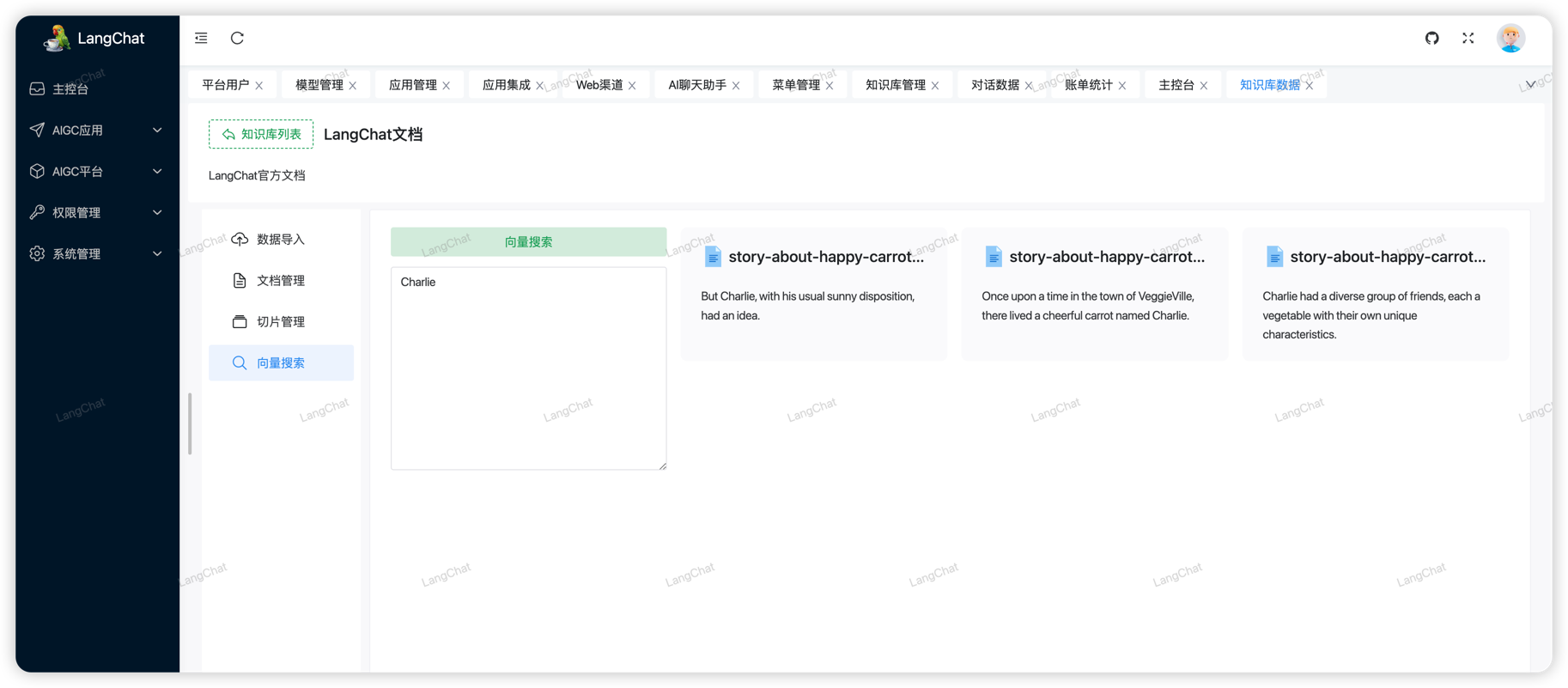
最终使用RAG系统检索后的数据也是通过这种方式交给模型分析处理的。